Here is the original japh.pl program:
@P=split//,".URRUU\c8R";@d=split//,"\nrekcah xinU / lreP rehtona tsuJ";sub p{
@p{"r$p","u$p"}=(P,P);pipe"r$p","u$p";++$p;($q*=2)+=$f=!fork;map{$P=$P[$f^ord
($p{$_})&6];$p{$_}=/ ^$P/ix?$P:close$_}keys%p}p;p;p;p;p;map{$p{$_}=~/^[P.]/&&
close$_}%p;wait until$?;map{/^r/&&<$_>}%p;$_=$d[$q];sleep rand(2)if/\S/;print
Here it is with some whitespace and reasonable variable names; I eliminated a couple of micro-obfuscations like the use of the \c8 character in @P.
1 @STATE = split //, ".URRUUxR";
2 @data = split//,"\nrekcah xinU / lreP rehtona tsuJ";
3
4 sub make_pipe_and_fork {
5 @pipestate{"r$fhno", "u$fhno"}=(P,P);
6 pipe "r$fhno", "u$fhno";
7 ++$fhno;
8 ($pid *= 2) += $is_child = !fork();
9 map {
10 $STATE=$STATE[$is_child ^ ord($pipestate{$_}) & 6];
11 $pipestate{$_} = (/^$STATE/i ? $STATE : close $_);
12 } keys %pipestate
13 }
14 make_pipe_and_fork;
15 make_pipe_and_fork;
16 make_pipe_and_fork;
17 make_pipe_and_fork;
18 make_pipe_and_fork;
19
20 map {
21 $pipestate{$_} =~ /^[P.]/ && close $_
22 } %pipestate;
23
24 wait until $?;
25
26 map { /^r/ ? <$_> : 1 } %pipestate;
27
28 $_ = $data[$pid];
29 sleep rand(2) if /\S/;
30 print
I recommend that you follow the code in a second window while reading the rest of the description below. Numbers in [square brackets] are the line numbers of the expanded source code.
The program forks thirty-two copies of itself. Each copy is responsible for printing exactly one character from @data. Because the 32 processes are running concurrently, they somehow need to synchronize themselves so that the thirty-two characters come out in the right order. They use two mechanisms to accomplish this: First, parents wait for their children to complete before printing and exiting. Second, the processes use pipes to communicate to one another when they are finished. About half the program logic is concerned with the details of setting up the pipes correctly.
The heart of the program is the five calls to make_pipe_and_fork [14-18] Each call makes a pipe and forks. Since every process follows the same code path, each call to make_pipe_and_fork doubles the number of running processes: After the first call, there are two processes; each one then calls make_pipe_and_fork, so there are four processes after the second call. After the fifth call, there are thirty-two processes running.
At the end of the program, each of the thirty-two processes selects an element of @data [28] and prints it [30]. The string to be printed is stored in the @data array [2] and since the thirty-two processes run concurrently, the question is why the characters come out in the correct order, especially given the presence of the random sleep [29].
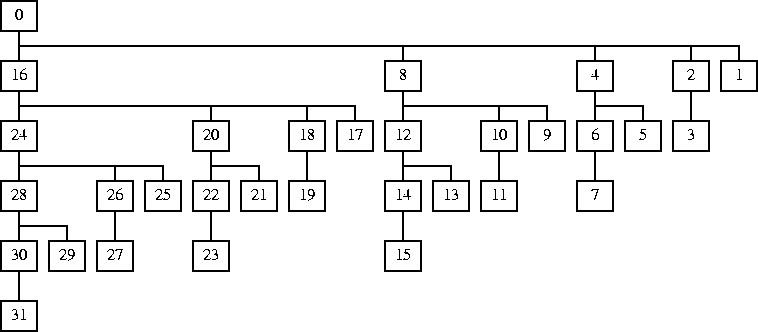
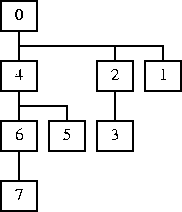
To understand how the processes synchronize, we have to understand how they are related.
Numbers here denote the values that eventually end up in $pid [8]. Process 0 is the initial process. It forks five times, creating the processes that eventually become 16, 8, 4, 2, and 1. 1 is the result of the last fork; since there are no more forks, 1 has no children. 2 is the result of the next-to-last fork, since it executes one more fork, it creates its own child, which is 3. 16 is the result of the first fork; it forks four more times, yielding children 24, 20, 18, and 17.
The numbers are computed as follows. Initially, the only process is number 0. Each time a process forks, it doubles its $pid, and the child process adds 1 to its pid [8]. Initially, there is only one process, and $pid defaults to 0. After the first fork, there is a child process which has inherited the 0:

Both processes double their $pids, and the child process increments its $pid, yielding:

After the second fork, we have:
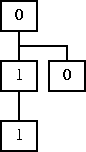
The original parent has created a child process which inherits its $pid of 0, and the child from the first fork, whose $pid is 1, has created another new child which inherits the 1. Then each process doubles its pid:
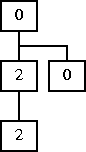
And the new children add 1 to their pids:
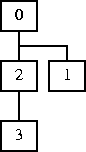
Continuing in this way yields the tree of figure 1. It's worth noticing that if you write each process' $pid in binary, it records how the process was created. A 0 bit means that the process was descended from the parent process after a fork; a 1 bit means that it was descended from the child after the fork. For example, process 0 was the parent in each of the five forks; process 1 = 00001 was the parent after the first fork, and only differentiated from 0 in the final fork, in which it was the child.
The $pid variable is used at the end [28] to select which character of @data the process prints. Since the last character to be printed is $data[0], we need to ensure that process 0 prints last; similarly we want process 28 to print after 29, 30, and 31, but before the others.
Looking at the chart, we see that the rule is: Each process must print after its own descendants and after its own elder siblings. This isn't quite enough: Looking at process 3, we see that it must also wait for 4, so processes must wait for their ancestors' elder siblings as well.
There are two synchronization rules. The first is that a parent process always prints after its children. This is accomplished by the wait loop [24]. wait waits for a child to terminate, and places the process' exit status into $?. Since children exit by falling off the program, they exit with a status of 0; this value is placed into $?, and the until loop in the parent continues. When there are no children left, the wait call returns an error and places -1 into $? (this is an undocumented feature) and the until loop exits. Process 0 executes this loop six times, once for each of its five children and once more to exit; process 1, which has no children, executes the loop once.
This rule is not enough, because although it ensures that 2 follows 3 and that 0 follows 1 and 2, it does nothing to ensure that 1 follows 2. This is accomplished with pipes and is more complicated. Let's consider just processes 0-7 for a while:
We need to arrange the following:
This is enough, because all the other necessary waiting is taken care of by the wait loop [24]. The additional waiting is handled with pipes. We arrange that there is a pipe from process 2 to processs 1, from 4 to 3, and from 6 to 5. The odd-numbered processes try to read from the pipes, and block waiting for input. The even-numbered processes ignore the pipes. When an even-numbered process exits, the writing end of its pipe is closed, the reading process on the other end gets an end-of-file read, and continues.
Setting up the pipes is quite complicated because parents have to set up pipes, keep them open while they fork two children, and then close them. (If the parents did not close the pipes, then the children would end up waiting for their parents to close them; since the parents are waiting for the children to exit; this would cause deadlocks.)
To arrange this, we associate a state with each pipe. Each pipe has two filehandles, named rN (for the reading end) and uN (for the uriting end---sorry, I mean the writing end) where N is some number [6]. The N is stored in the $fhno variable and is kept unique within each process simply by incrementing it each time it is used [7].
The state records whether the pipe has been inherited by one or two children so far, and whether it is for reading or for writing. A hash, %pipestate, maps filehandle names to states. Since each pipe has two filehandles, there are actually two entries in %pipestate for each pipe.
There are five possible states, called P, x, U, . (period), and R. The array @STATE is a transition table that says how the states should change as the program runs. The transition occurs in make_pipe_and_fork after the fork [9-12]. Each filehandle is examined in turn and its state is transited according to the state table. The state table is actually two-dimensional, because the transitions are different depending on whether the process was a parent or a child of the last fork. Parent-childness is recorded by the $is_child variable following the fork [8].
x turns out to be unimportant: The program computes state transitions from x, but they are ignored since handles in that state have already been closed. (The transitions turn out to be the same as those for state P, but this is an irrelevant artifact of the program's construction.)
The indexing into the state table is done by the ord expression [10]. The binary values of the characters P, R, U, and . are:
char binary binary&6
P 01010000 000 = 0
R 01010010 010 = 2
U 01010101 100 = 4
. 00101110 110 = 6
The index into the @STATE table is (ord(old state)&6 + $is_child). $is_child is boolean, so the index is from 0 to 7, with 0 and 1 indicating the transitions from state P, 2 and 3 indicating the transitions from state R, and soforth. (Because of this computation, it turns out that the transitions from x are the same as those from P, but the x transitions have no effect on the program's behavior.)
The @STATE table, which contains ".URRUxxR" is actually interpreted like this:
Old state: Parent Child
P . U
R R R
U U x
. x R
Figure 2
Now, what do the states mean? There are two kinds of pipes in this program. One is the kind that a parent process only has open because its children needed to inherit it; once the two children have the pipe, the parent can (and should) close it. A state of P indicates that the pipe has not been inherited by any children yet. A state of . indicates that the pipe has been inherited by the writing child but not yet by the reading child. A state of x indicates that the pipe has been inherited by both children and should be closed.
In the children, pipes are marked with U which indicates that the pipe is for writing, or with R for reading.
P is the initial state, assigned to both ends of each new pipe just after the pipe is created [5]. After a fork, the parent changes P to ., which indicates that the pipe has been inherited by the writing child. The child has inherited a P pipe and changes its state to U, which indicates that the pipe is for writing. (See the first line of figure 2.)
Now the parent forks again. The new child inherits its . pipe and changes the state to R indicating that the pipe is for reading. The parent changes the state to x. (See the bottom line of figure 2.)
After a fork, if a parent process discovers that it has any R or U pipes, it leaves them alone and does not change the state, because these are the pipes that it inherited from its own parent that it will use to talk to its sibling. (See the second and third lines of figure 2.) Child processes inherit R pipes, and leave them alone so that they wait for their parents' elder siblings. They inherit U pipes, and change them to x and close them, so that their parents' younger siblings don't wait for them, although it doesn't matter because their parents' younger siblings will have to wait for them anyway. I put x there instead of U to make it a little more confusing.
I promised earlier that pipes in the x state would get closed. Also, a pipe in the R state should have its writing end closed, and one in the U state should have its reading end closed. If we didn't do this, then processes would deadlock: They'd wait for the writing ends to be closed, but that would never happen because they'd have the writing ends open themselves! Line [11] takes care of some of this closing. $_ is set to the name of the pipe filehandle, which is either "rN" or "uN". We look to see if the first character of the filehandle name matches the pipe state name; if so this is when we actually update the state; if not, we close the handle. Handles in state . never get closed because the pattern always matches. Writing handles "uN" get closed unless they're in state U, and reading handles "rN" get closed unless they're in state R. All filehandles get closed in state x. It's impossible for the state to be P here because there are no transitions into state P; the P's have already been changed to .'s or to U's. Incidentally, we set the state to 0 after closing a handle, but that doesn't matter because the handle has been closed.
There are some fine points here. Many processes, such as #1 above, end up holding the writing ends of pipes which are no longer open for reading. If any of these processes actually wrote to the pipe, they would get a SIGPIPE signal and abort. However, this never comes up.
Another fine point is that there are some leftover pipes in parents that need to be closed up. For example, a parent might have a . pipe that is marked U in the child but will never be inherited by anyone else. 0 holds such a pipe; 1 inherited the writing end, and 0 is not going to fork again to give anyone else the reading end. 0 needs to close this, or else 1 would wait for 0 to exit, which would be a disaster, because 0 is already waiting for 1 to exit. Lines [20-22] handle this: Each process looks to see if it has any leftover pipes in states P or ., and closes them if so. We do the loop over the keys and values of the hash just to save having to write keys, because I was almost out of space and needed to save four characters. It doesn't matter that we loop over values also, because when we use a value as a key the result always comes up null, so the pattern doesn't match.
Line [24] then waits until all the children are dead, as discussed earlier. Line [26] takes care of waiting until the pipes are closed. Again, we iterate over both keys and values, and again we're only interested in the keys. The values never match /^r/, so they're ignored, and similarly, the "uN" keys, which are writing pipes, are also ignored. But when we see a reading pipe "rN", we try to read a line from it. Now, we might have closed the handle already, in which case the filehandle read returns undef immediately. Otherwise, attempting to read from the pipe causes the process to block until the writing end is closed, which occurs when the process on the writing end exits. No process ever actually writes anything to the pipes.
Finally, having waited for all the children and all the upstream processes, the program loads $_ with the appropriate character from @data, sleeps at random to prove that the processes are really cooperating, and prints out its character. The if /\S/ test is there so that a process doesn't sleep before printing a space, because waiting for a space to come out is boring.
This explanation Original source code ---------------- -------------------- $pid $q @data @d $fhno $p %pipestate %p $is_child $f @STATE @P make_pipe_and_fork p
I am not really interested in micro-obfuscations. If I could have submitted the program with the whitespace and variable names still intact, I would have. I formatted it in a small block only because I wanted to use the program as a Usenet signature, and it needed to fit in four lines of 78 characters.
Nevertheless, there are a few minor obfuscations lurking below the surface that I haven't mentioned yet.
The @P array is initialized to split //, ".URRUU\c8R". What is \c8? Normally \c means a control character, but there is no such character as control-8.
The actual meaning of \cX in Perl is this: If X is a letter, it is first converted to uppercase. Then the 64 bit of X is inverted. That is, Perl effectively computes chr(ord(uc X) ^ 64).
All the capital letters have the 64 bit on, so this process subtracts 64 from the character code of a capital letter, turning capital E (code 69) into character \005 (69^64=5). But the same process applies in less well-known cases also. The character code for ? is 63, so \c? is the character with code 63^64 = 127. This is the DEL character.
There is no such character as control-8, but Perl applies the same transformation. The character code for 8 is 56, so \c8 is character number 56^64 = 120, which happens to be lowercase x. If you try perl -le 'print "\c8"' you'll see that it simply prints out a lowercase letter x.
I could have saved a couple of characters when I wrote the array index expression $f^ord($p{$_})&6, by using $f^6&ord$p{$_} instead. Characters were very precious, but I shaved a couple of extras to use here, because I liked having the implied fnord lurking in my program. The line break was carefully positioned, to leave f^ord by itself at the end of the line.
In the version of the program I submitted to TPJ, I had $f|ord instead of $f^ord. I didn't realize until later that I could use ^, which is slightly more n-like (and slightly more confusing) in place of |.
I wanted all the lines to be the same length, and the third line of the source code was two characters short. The easiest way to fix this was to insert some white space. I realized that I could get an easy micro-obfuscation here by changing /^$P/i to / ^$P/ix. The caret in the middle of the regex was sufficiently odd-looking that it confused a few people briefly, even though the /x renders the initial space inoperative.
This depends on an undocumented feature. It assumes that a failed wait() call will set $? to a nonzero value. It does do this (it always sets it to -1) but that is not documented anywhere. (The return value of wait is documented to be -1 in this case, but the man pages only say what happens to $? in case of a successful call.)
I spent a lot of effort trying to make this more interesting. For example, it seemed plausible that by tinkering the program a little bit, I could make it say SHEESH. I wrote some programs to exhaustively search all the possible transition tables, looking for something interesting, but the best I could come up with were things like pv.peeve and ae.added, so I left it alone.
This is my favorite part of the program. I love the way it looks. I hoped that when someone looked at the program for the first time this is what would jump out at them. I want them to wonder what it could possibly mean and why are there five p's?
Of course, it has to be five p's to create 25 processes, one for each character in the 32-character @d array. The program will print longer strings, but you need to add more p's. Some people have suggested that it will fail unless @d is a power of 2, but they are mistaken; the program works fine. In fact, the version of the program that I actually submitted to the contest prints out The Perl Journal\n, which is 17 characters. In this case, some of the processes load $_ with an undefined value, which prints out as the empty string.
I originally planned to have the program say Just another Perl hacker, but I decided I might as well take advantage of the extra room to get more data into the @d array. The program is at least as much a display of Unix obfuscation as it is a display of Perl obfuscation, and it's fitting that the output acknowledges that.
I have wanted to write an obfuscated program for a long time, but I was never any good at it. I briefly considered entering the IOCCC many years ago, but I didn't have any good ideas. I considered something laughably simple involving a lot of nested ?...: expressions, and found that my habits toward simple, clear code were impeding me. I gave up.
This program probably wouldn't have been written without the help of Abigail. In March, Abigail gave a talk to the Philadelphia Perl Mongers about writing JAPHs and other obfuscated programs. This program was directly inspired by the talk. I had been thinking on and off about this program for years, but it was Abigail's talk that finally galvanized me to write it. (Abigail's extremely clever slides are available online, and everyone is sure to be amused and amazed by them.)
The original conception of the program was pretty much as you see here: I knew I wanted a tree of processes, synchronized by pipes and wait. What I didn't realize was how complicated the pipe structure would have to be; I spent substantial chunks of two or three days figuring out how it would have to work. I also don't think I realized until later that it was unnecessary to actually write anything into the pipes. The biggest single flash of inspiration I had was the one that led to the &6 part. I really like that part.
The depth of the obfuscation comes from the pipes, so unlike many ofbuscated programs, it should translate well to other languages. I've considered rewriting the program in C. But C has no hashes or pattern matching, which I depend on, so a lot of the program logic would have to change.
On the other hand a version in Python would probably be easy to do. I don't think the program is substantially less obfuscated once you put the whitespace back in. I believe that true obfuscation doesn't come from a lot of punctuation characters or a lack of whitespace. I think if you were to translate my program into Python, it would be about equally impossible to understand. I hope to do a Python translation soon to see how it comes out.

Return to: Universe of Discourse main page | What's new page | Perl Paraphernalia | Obfuscation