http://perlmonks.plover.com/index.pl?node_id=88943&lastnode_id=3989
bugs.perl.org/perlbug.cgi?req=bug_id&bug_id=20010319.032
1 #!/usr/bin/perl
2 use strict;
3
4 sub making_of_list {
5
6 my $ftp="c:/ftproot";
7 opendir (FTP, $ftp) || die $!;
8 my @file = readdir FTP;
9 close FTP;
10 my $a=0;
11 foreach (@file) {
12
13 open (FILES, "+>>c:/docu/ftproot.txt") || die $!;
14 if ("$file[$a]" =~ /txt/i) {
15 print FILES $file[$a],"\n";
16 } elsif ("$file[$a]" =~ /doc/i) {
17 print FILES $file[$a],"\n";
18 } elsif ("$file[$a]" =~ /mpd/i) {
19 print FILES $file[$a],"\n";
20 } elsif ("$file[$a]" =~ /mta/i) {
21 print FILES $file[$a],"\n";
22 }else {
23 }
24 $a++;
25 close FILES;
26 }
27
28 ############################################################
29
30 sub copy_from_root {
31
32 use File::Copy;
33 my $ftplist = "c:/docu/ftproot.txt";
34 open (FILE, $ftplist) || die $!;
35 my @disk = ;
36 chomp @disk = ;
37 $b = 0;
38 foreach (@disk) {
39 my $report = $disk[$b];
40 print $report,"\n";
41 if ("$report" =~ /^afinv/i) {
42 my $reports = $report;
43 $reports =~ s/.mta/.mpd/ig;
44 my $truth="c:/scripts/attempt/$reports";
45 my $inv="c:/invoice/$reports";
46 my $apollo="c:/reports/$reports";
47 my $daym=(localtime(time()))[3];
48 my $afis3="c:/afis3too/$daym/$reports";
49 my $source = "c:/ftproot/$report";
50 foreach my $dest ($truth, $afis3, $apollo, $inv) {
51 copy ($source, $dest);
52 }
53 unlink $source;
54 } elsif ("$report" =~ /^csinv/i) {
55 my $reports = $report;
56 $reports =~ s/.mta/.mpd/ig;
57 my $truth="c:/scripts/attempt/$reports";
58 my $inv="c:/invoice/$reports";
59 my $apollo="c:/reports/$reports";
60 my $daym=(localtime(time()))[3];
61 my $afis3="c:/afis3too/$daym/$reports";
62 my $source = "c:/ftproot/$report";
63 foreach my $dest ($truth, $afis3, $apollo, $inv) {
64 copy ($source, $dest);
65 }
66 unlink $source;
67 } elsif ("$report" =~ /^sfinv/i) {
68 my $reports = $report;
69 $reports =~ s/.mta/.mpd/ig;
70 my $truth="c:/scripts/attempt/$reports";
71 my $inv="c:/invoice/$reports";
72 my $apollo="c:/reports/$reports";
73 my $daym=(localtime(time()))[3];
74 my $afis3="c:/afis3too/$daym/$reports";
75 my $source = "c:/ftproot/$report";
76 foreach my $dest ($truth, $afis3, $apollo, $inv) {
77 copy ($source, $dest);
78 }
79 unlink $source;
80 } elsif ("$report" =~ /doc/i) {
81 my $reports = $report;
82 $reports =~ s/doc/txt/ig;
83 my $truth="c:/scripts/attempt/$reports";
84 my $apollo="c:/reports/$reports";
85 my $daym=(localtime(time()))[3];
86 my $afis3="c:/afis3too/$daym/$reports";
87 my $source = "c:/ftproot/$report";
88 foreach my $dest ($truth, $afis3, $apollo) {
89 copy ($source, $dest);
90 }
91 unlink $source;
92 } elsif ("$report" =~ /mta/i) {
93 my $reports = $report;
94 $reports =~ s/.mta/.mpd/ig;
95 my $truth="c:/scripts/attempt/$reports";
96 my $apollo="c:/reports/$reports";
97 my $daym=(localtime(time()))[3];
98 my $afis3="c:/afis3too/$daym/$reports";
99 my $source = "c:/ftproot/$report";
100 foreach my $dest ($truth, $afis3, $apollo) {
101 copy ($source, $dest);
102 }
103 unlink $source;
104 } else {
105 my $reports = $report;
106 my $truth="c:/scripts/attempt/$reports";
107 my $listing="c:/scripts/fink.txt";
108 my $apollo="c:/reports/$reports";
109 my $daym=(localtime(time()))[3];
110 my $afis3="c:/afis3too/$daym/$reports";
111 my $source = "c:/ftproot/$report";
112 foreach my $dest ($truth, $afis3, $apollo) {
113 copy ($source, $dest);
114 }
115 unlink $source;
116 }
117 my $listing="c:/scripts/fink.txt";
118 open (LST,"+>>$listing")or die "$!";
119 my $paper = sprintf("%.6s", $report);
120 my $bbat=".bat";
121 my $pap=join("",$paper,$bbat);
122 $pap =~ tr/a-z/A-Z/;
123 print LST $pap,"\n";
124 close LST;
125 $b++;
126 }
127
128 }
129 ############################################################
130
131 sub make_list_for_batches {
132
133 my $lst = "c:/scripts/fink.txt";
134
135 open (LST, $lst) || die $!;
136 my (@array, %hash);
137 foreach () {
138 push (@array, $_) unless (defined($hash{$_}));
139 $hash{$_} = 1;
140 };
141 close (LST);
142 open (LST, ">$lst") || die $!;
143 print LST join("", @array);
144 close (LST);
145 }
146
147 ############################################################
148
149 sub this_gets_a_listing_of_the_batch_files {
150
151 my $bats="c:/reports";
152 opendir (BATS, $bats) || die $!;
153 my @bat = readdir BATS;
154 close BATS;
155 my $r=0;
156 foreach (@bat) {
157 if ("$bat[$r]" =~ /bat/i) {
158 open (STAB, "+>>c:/scripts/bats.txt") || die $!;
159 print STAB $bat[$r],"\n";
160 }
161 $r++;
162 }
163 close STAB;
164 }
165
166 ############################################################
167
168 sub wow {
169
170 my $batch="c:/scripts/bats.txt";
171 my $fink = "c:/scripts/fink.txt";
172 my $wow="c:/scripts/wow.txt";
173 open (BAT, "+$batch") or die $!;
174 open (LST, "+$fink") or die $!;
175 my @batch = ;
176 my @lst = ;
177 my $c = 0;
178 foreach (@lst){
179 my $sub=$lst[$c];
180 my $d=0;
181 foreach (@batch){
182 my $sub2 = $batch[$d];
183 if ("$sub2" =~ /$sub/ig){
184 open (WOW, "+>>$wow") or die $!;
185 print WOW $batch[$d];
186 print "Working...\n";
187 }$d++;
188 }$c++;
189 }
190 close BAT;
191 close LST;
192 close WOW;
193 }
194
195 ############################################################
196
197 sub run_the_batches {
198
199 my $copy="c:/scripts/wow.txt";
200 open (COPY, "+$copy") || die $!;
201 my @co = ;
202 chomp @co = ;
203 my $s=0;
204 my $output = "c:/reports/$co[$s]";
205 foreach (@co) {
206 system ($output);
207 $s++;
208 }
209
210 }
211
212 ############################################################
213
214 sub delete {
215
216 my $fink = "c:/scripts/fink.txt";
217 my $bat = "c:/scripts/bats.txt";
218 my $wowo = "c:/scripts/wow.txt";
219 my $ftpr = "c:/docu/ftproot.txt";
220
221 open (FINK, "+>$fink") || die "$!";
222 open (BAT, "+>$bat") || die "$!";
223 open (WOW, "+>$wowo") || die "$!";
224 open (FTP, "+>$ftpr") || die "$!";
225
226 unlink ;
227 unlink ;
228 unlink ;
229 unlink ;
230
231 }
232
233 #
234 #
235 #
236 #
237 #
238 ############################################################
239
240 ############################################################
241
242
243 print "\n\n\n";
244 print " Robco Inc. Presents : \n\n\n";
245 print " The NEW, AMAZING, INCREDIBLE ....\n\n\n";
246 print " Robco Document Rotisserie!!!!!\n\n\n";
247 print "Just RENDER it, THEN don't REMEMBER it!!!!!\n\n";
248 print " It's just that easy.\n\n\n\n\n";
249
250 while (1) {
251
252 my $clock = localtime;
253 print $clock,"\n";
254 print "sleeping .... ZzZzZzZzZz......\n";
255 sleep (10);
256 print "OK! OK! .... I'm awake! .... I'm awake\n";
257 ©_from_root;
258 &make_list_for_batches;
259 &this_gets_a_listing_of_the_batch_files;
260 &wow;
261 &run_the_batches;
262 &delete;
263 &making_of_list;
264 }
This is a terrible program for two reasons. The first reason is
obvious: It is much, much too big. Because of this, I can't figure
out what it is doing. So I needed to make two major passes on it.
First, I needed to cut down the code size to something manageable.
Once the code was reduced by 50 percent, I began to realize the other
big problem: The program repeats the same work over and over, creating
the same big temp files, processing them, and throwing them away
again. With the code cut down, it began to be apparent how to fix
this. I'll tell the story of how I reduced this program by ******.
The biggest target seems to be the C subroutine. The
bulk of the function is six nearly identical sections of code like
this one:
41 if ("$report" =~ /^afinv/i) {
42 my $reports = $report;
43 $reports =~ s/.mta/.mpd/ig;
44 my $truth="c:/scripts/attempt/$reports";
45 my $inv="c:/invoice/$reports";
46 my $apollo="c:/reports/$reports";
47 my $daym=(localtime(time()))[3];
48 my $afis3="c:/afis3too/$daym/$reports";
49 my $source = "c:/ftproot/$report";
50 foreach my $dest ($truth, $afis3, $apollo, $inv) {
51 copy ($source, $dest);
52 }
53 unlink $source;
These six sections represent a serious maintenance problem. Here's
why: It took me, an experienced programmer, about half an hour to
figure out what the differences were between these six sections. It
wasn't a diffiult task, but it was time-consuming, simply because the
code was repeated so very many times. Here is the summary of the 69
lines of code: The first three sections, which concern
C, C, and C, are identical.
They differ from the C section only in that C omits the
invoice report. C differs from the C section only in the
C line. The C clause differs from C only by omitting
the C and by setting C<$listing>, a variable that is never used.
Now that we understand the differences, it's easy to collapse these 69
lines to 17:
{
my $reports = $report;
if ($reports =~ /^{af,cs,sf}inv/i
|| $reports =~ /mta/i) {
$reports =~ s/.mta/.mpd/ig;
} elsif ($reports =~ /doc/i) {
$reports =~ s/doc/txt/ig;
}
my $truth="c:/scripts/attempt/$reports";
my $apollo="c:/reports/$reports";
my $daym=(localtime(time()))[3];
my $afis3="c:/afis3too/$daym/$reports";
my $source = "c:/ftproot/$report";
foreach my $dest ($truth, $afis3, $apollo) {
copy ($source, $dest);
}
if ($reports =~ /^{af,cs,sf}inv/i) {
my $inv="c:/invoice/$reports";
copy($source, $inv);
}
unlink $source;
}
Now we can clean this up. The code contains many examples of the
I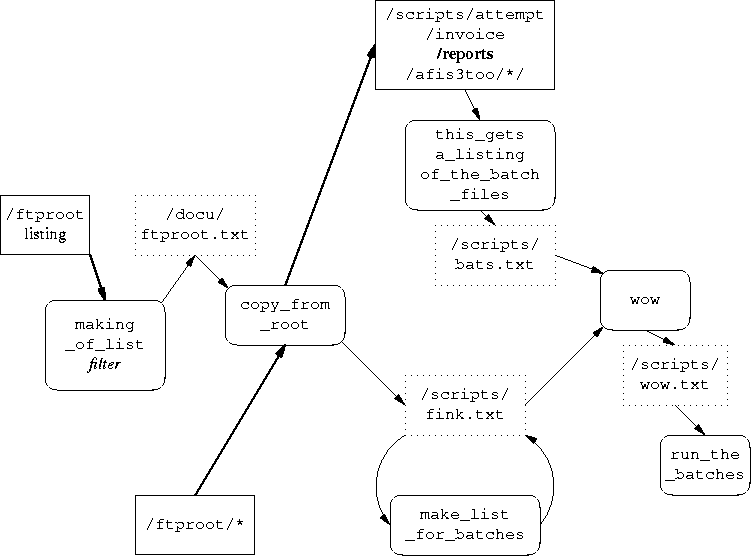
Isn't this amazing? Here, boxes with rounded corners represent
functions in the program, and boxes with square corners
represent the files or directories that the functions operate on.
Dotted boxes are temporary files that will be cleaned up by the
C function after each run. Light arrows represent a flow of
information: Typically the names of files. Heavy arrows indicate
that bulk data (that is, entire files) are being copied.
After I had stared at this for a while with my mouth open, a creeping
suspicion came over me. The flow here is very complicated, and the
parts must be run in the correct order, since each manufactures data
for the next one to use. C must run first, followed
by C, followed by C and
C, followed by C, with
C last of all. I was suddenly struck by a fear that
the program might run the functions in the correct order. Here's the
main control:
©_from_root;
&make_list_for_batches;
&this_gets_a_listing_of_the_batch_files;
&wow;
&run_the_batches;
&delete;
&making_of_list;
Oh, no! The very first thing the program does is call
C. But as we can see from the diagram,
C requires the file C, which is
manufactured by C, which is run I. I don't know
how this could have escaped detection sooner, but it can't be good.
Now I understood several things better. I had an overview of what the
program was doing. I realized why it was so big: The author doesn't
know how to use arrays! Every time he wants to filter or process a
list of filesnames, he writes them out to a file. It seems pretty
clear that we can replace all of the dotted boxes in the diagram with
array variables and eliminate most of the file management.
So we now have a higher-level goal: Eliminate all four of the
temporary files, replacing them with arrays. Let's begin at the
beginning, with C:
sub making_of_list {
opendir (FTP, "C:/ftproot") or die $!;
open (FILES, ">> c:/docu/ftproot.txt") or die $!;
while (my $file = readdir FTP) {
if ($file =~ /txt|doc|mpd|mta/i) {
print FILES $file,"\n";
}
}
closedir FTP;
close FILES;
}
This function reads a directory, filters out some of the filenames,
and writes a temporary file with the names of the files of interest.
Instead of a temporary file, let's have it just return a list of the
filenames:
sub making_of_list {
my @result;
opendir (FTP, "C:/ftproot") or die $!;
while (my $file = readdir FTP) {
if ($file =~ /txt|doc|mpd|mta/i) {
push @result, $file;
}
}
closedir FTP;
return @result;
}
Here we're just performing a filter operation, selecting interesting
items from a list of filenames.
This is such a common operation that perl has a special built-in
operator for it, called C:
sub making_of_list {
opendir (FTP, "C:/ftproot") or die $!;
my @files = readdir FTP;
my @result = grep /txt|doc|mpd|mta/i, @files;
closedir FTP;
return @result;
}
We give C a pattern and a list, and it returns the items from
the list that match the pattern. C here is in list context,
so it returns a list of all the files from the C directory,
instead of returning them one at a time, as before. Now we notice
that C<@files> is used only once, immediately after
it is assigned, so we can eliminate it:
sub making_of_list {
opendir (FTP, "C:/ftproot") or die $!;
my @result = grep /txt|doc|mpd|mta/i, (readdir FTP);
closedir FTP;
return @result;
}
The function was originally 19 lines long; after our first pass it was
8. Now it's 5. If we can do as well on the rest of the program, we
will reduce its 195 working lines of code to about 50. Let's see how
this pans out.
According to the diagram, C is next in the stream.
C does two things: It copies a lot of files from
C to various destinations, and it also constructs the first
draft of C. Later on we will remove the duplicates from
C,fink.txt>, and then C will use its contents. Here's the last
draft of C:
sub copy_from_root {
open (FILE, "c:/docu/ftproot.txt") or die $!;
open (PATS, ">> $patterns") or die "$!";
while () {
...
my $pap = sprintf("%.6s", $_) . ".bat";
$pap =~ tr/a-z/A-Z/;
print PATS $pap,"\n";
}
close PATS;
close FILE;
}
The first change is that C won't read from
C; we got rid of that temporary file when we rewrote
C a minute ago. Instead, C will get
an argument list which tells it which files to copy. We can eliminate
all the code relating to C, and replace the main C loop
with a C loop that loops over the argument list:
sub copy_from_root {
open (PATS, ">> $patterns") or die "$!";
foreach (@_) {
...
my $pap = sprintf("%.6s", $_) . ".bat";
$pap =~ tr/a-z/A-Z/;
print PATS $pap,"\n";
}
close PATS;
}
Now, instead of writing out the pattern list to a patterns file, we'll
just make a list of the patterns and return the list:
sub copy_from_root {
my @pats;
foreach (@_) {
...
my $pap = sprintf("%.6s", $_) . ".bat";
$pap =~ tr/a-z/A-Z/;
push @pats, $pap;
}
return @pats;
}
We didn't save any code here yet, but we did make the program a lot
less complicated. We don't have to worry about what happens if the
disk is full or if the C fails for some other reason. We don't
have to worry about what happens if a filename contains a newline
character. We don't have to worry about removing the patterns file.
This simplicity is a benefit itself, and it will also yield more
benefits later because we will be able to reduce the size of other
parts of the code.
Next we can take care of C. It reads the
patterns file, eliminates the duplicates, and writes them back out
again.
131 sub make_list_for_batches {
132
133 my $lst = "c:/scripts/fink.txt";
134
135 open (LST, $lst) || die $!;
136 my (@array, %hash);
137 foreach () {
138 push (@array, $_) unless (defined($hash{$_}));
139 $hash{$_} = 1;
140 };
141 close (LST);
142 open (LST, ">$lst") || die $!;
143 print LST join("", @array);
144 close (LST);
145 }
If we eliminate the patterns file, we're left with a function
that gets a list of patterns and returns the same list with the
duplicates removed:
sub make_list_for_batches {
my (@array, %hash);
foreach (@_) {
push (@array, $_) unless (defined($hash{$_}));
$hash{$_} = 1;
};
return @array;
}
This cuts the function from 11 to 6 lines. We can do better though.
When the function has finished running, every item in C<@array> is
also a key in C<%hash>. If we could get a list of the keys, we
wouldn't need C<@array> at all. In Perl, we can get the list of keys
from a hash with the C function:
sub make_list_for_batches { #
my (%hash); #
foreach (@_) {
$hash{$_} = 1;
};
return keys %hash; #
}
Of these five lines, the tree marked with C<#> signs are structural.
This means that they don't relate to what we really want to
accomplish, which is to remove duplicates from a list; they are only
there because we happened to use a function to accomplish our task.
There are many reasons to have functions that are nearly all
structural; one of the most important is for documentative purposes.
But here the function's name isn't serving any such purpose. We can
eliminate the entire finction by having C return the
list of patterns with the duplicates already removed:
sub copy_from_root {
my %pats;
foreach (@_) {
...
my $pap = sprintf("%.6s", $_) . ".bat";
$pap =~ tr/a-z/A-Z/;
$pats{$pap} = 1;
}
return keys %pats;
}
This costs nothing in C; the code hardly changed at
all. In return, we can eliminate C entirely.
The original function was 11 lines long; we cut it first to 5 and then
to 0.
We've accomplished half of our goal of getting rid of the four
temporary files. Next on the list is C, which is
produced by the function named
C:
sub this_gets_a_listing_of_the_batch_files {
my $bats="c:/reports";
opendir (BATS, $bats) || die $!;
my @bat = readdir BATS;
close BATS;
my $r=0;
foreach (@bat) {
if ("$bat[$r]" =~ /bat/i) {
open (STAB, "+>>c:/scripts/bats.txt") || die $!;
print STAB $bat[$r],"\n";
}
$r++;
}
close STAB;
}
To save your sanity and mine, let's rename this function what it
should have been called in the first place: C. We
can also fix some bugs: C is a directory handle, so we need to
close it with C, rather than C. (Perl would have
emitted a warning about this if it had been run with the C<-w> flag.)
Since C is already looping over C<@bat>, setting C<$_> to
each element in turn, we can eliminate C<$r>. Normally we would want
to move the C outside the loop, but since we're planning to get
rid of C entirely, we won't bother:
sub list_batch_files {
opendir (BATS, "c:/reports") || die $!;
foreach (readdir BATS) {
if (/bat/i) {
open (STAB, "+>>c:/scripts/bats.txt") || die $!;
print STAB $bat[$r],"\n";
}
}
closedir BATS;
close STAB;
}
We want the function to return a list of batch files, rather than
writing the list into C<"c:/scripts/bats.txt">:
sub list_batch_files {
my @batch_files;
opendir (BATS, "c:/reports") || die $!;
foreach (readdir BATS) {
if (/bat/i) {
push @batch_files, $_;
}
}
closedir BATS;
return @batch_files;
}
It's now apparent this this is just a filtering operation such as the
one we performed in C, so we can replace the whole
thing with a simple C:
sub list_batch_files {
opendir (BATS, "c:/reports") || die $!;
my @batch_files = grep /bat/i, (readdir BATS);
closedir BATS;
return @batch_files;
}
The function has gone from 12 lines to 5. If we wanted to shorten it
still further, we could use the Perl C operator, which reads the
list of files from a directory, doing the C and C
implicitly:
sub list_batch_files {
return grep /bat/i, glob("c:/reports");
}
The next function in the chain is C, which takes the output from
and C and produces the list of
batch files that are executed. C has produced a list
of potential batch files, and
----------------------------------------------------------------
I have a few notes about this. It was a lot of work to fix this
program, and at several points I realized it would be a lot quicker to
just throw the whole thing away and start pver from scratch; probably
about fifty percent quicker. But the techniques I showed for fixing
bloated and broken programs are applicable even for examples that
aren't as bloated and broken as this one was.
One thing I'd like to stress is that even though I spent a lot of time
complaining about how awful this program was, it wasn't actually
atypical. I'm doing a class at TPC this year called 'Program Repair
Shop and Red Flags', and one thing I've learned is that most beginner
code is much, much worse than I imagined, and not for the reasons I
would have guessed. The number one lesson I've learned from Program
Repair Shop is this: beginners write way, way too much code. This
program is a I example.
That suggests that the warning messages produced by C<-w> and
C are not actually helping in the right places. They may be
helpful to experienced programmers, but for beginners they're just
nitpicking. Adhering to 'strict' may make a beginner's program 1%
less crappy, but the typical beginner program could be 50% less crappy
and it would still stuck big-time. The program I just showed was
strict-clean and it blew big steaming goat chunks---'strict' didn't
help. If the author had taken the effort he put into making it
strict-clean and put it into reducing repeated code, he would have
gotten a lot more payoff for his effort. Maybe it wouldn't have been
strict-clean, but it might have been somewhat less of a giant swamp.