pipe(F_IN, F_OUT) or die "pipe: $!"; write F_OUT;
Only a couple of weeks after I wrote about The Secret Passage, a discussion sprang up on the `Fun With Perl' mailing list about how to write formatted data (with Perl's format and write facilities) into a variable. The feature has been in Perl since Perl 1, but it only writes data to a file handle. In Perl 5, some extra hooks (formline, $^A) were added so that you could get the formatted output without actually printing it, but in Perl 4 and earlier you had to resort to trickery.
One technique you could use in Perl 4 was to open a temporary file, write the formatted data to the file, and then read it back. Someone complained about having to clean up the file afterwards, so another suggestion was made: You can open a pipe to a child process, write the formatted data down the pipe, and have the child send it back up the pipe; then there's no temporary file. Of course, you now have to clean up the child process, and it won't work on systems without fork. (I don't think Perl 4 ran on any such systems, so it's a pointless objection, but never mind that.)
Anyway , as soon as I saw this a light went on in my head and I said ``Aha! Here is an application for the Secret Passage.'' As you may recall, The Secret Passage is a technique for printing data that has been filtered by a child process, but without the child process. I wrote it up, and it worked OK. Source code is available if you want to see it.
But then Randal Schwartz pointed out that using the Secret Passage here is really dumb. There's no point in the program execing itself; it might as well read the data out of the pipe without the exec.
An advantage of the execless version is that you can read the data out of the pipe after every write, so you don't have to worry as much that the pipe will fill up before you're done writing. The code looks like this:
#!/usr/bin/perl
#
# This demonstrates a method of writing format-ed output into
# variables under Perl 4.
#
# mjd-perl-lod@plover.com
format F_OUT =
@<<<<<<<<< | @|||||||||| | @>>>>>>>>>> @#####.##
$left, $center, $right, $numeric
.
pipe(F_IN, F_OUT) or die "pipe: $!";
select((select(F_OUT),$|=1)[0]);
$numeric = 11;
for ($i=0; $i<7; $i++) {
($left, $center, $right) = split /\s+/, scalar <DATA>;
write F_OUT;
push @formatted, scalar <F_IN>;
$numeric *= 2 / 3;
}
for ($i = 0 ; $i < @formatted; $i++) {
print "STDIN $i: $formatted[$i]";
}
__DATA__
In the beginning
God created the
heavens and the
Earth. The Earth
was without form
and void, and
darkness was upon
the face of
the deep.
This looks really good, and might even serve as a general solution to the `Do a formatted write into a variable in Perl 4. I could probably package which up into a module that provides a Perl 4 workalike for formline and $^A.
grep ?foo?, @list;
This is a great hack that doesn't work yet.
Here's the problem it's intended to solve: People often want to use grep to detect whether or not a certain item is present in a list. Then they say something like this:
if (grep /Dominus/, @list) {
# Dominus is in the list
}
The problem with this is that if the list is very long, it is wasteful. grep searches the entire list looking for all the occurrences of Dominus, even if it finds one right up front.
You might want Perl to optimize this use of grep, but it is hard to do that. People also use grep to find the number of occurrences, and for that it does have to go all the way to the end. And grep is also allowed to modify the list. You'd have to be careful not to optimize this:
@numbers = (2, 4, 6);
if (grep $_ *= 2, @numbers) {
# Dominus is in the list
}
Because if it were optimized to stop the grep early, @numbers would end up with (4, 4, 6) instead of (4, 8, 12).
But there's a trick we can use. There's a very little-known Perl feature that says that if you do a pattern match operation, and the pattern delimiters are question marks, then the pattern will only match once. After the first match, Perl doesn't even bother to check to see if it matches; it just returns instant failure.
That means that Perl knows that grep ?Dominus?, @list is going to return at most one match, and Perl can stop and bag out when you see the first one, because subsequent list elements can't match.
Unfortunately, this optimization isn't implemented yet. Even if you use ?...?, it still goes all the way to the end. And it doesn't help at all with tests like this one:
if (grep $_ % 2 == 0, @numbers) {
# The list contains even numbers
}
But a little bit of optimization is better than none, and it would be fun to be able to get some use out of the ?...? feature.
This brings up a related issue, which is that tie defeats optimization. Any time anyone proposes a Perl optimization, you can foil them by pointing out that it won't work in the presence of tied variables. Let's take a common example: Removal of invariants from a loop. This optimization takes a loop like this:
for $i (...) {
$j = 2**sqrt($k);
# Do something with $j
}
And replaces it with this:
$tmp = 2**sqrt($k);
for $i (...) {
$j = $tmp;
# Do something with $j
}
As long as $k doesn't change inside the loop, this works, because fetching a value is idempotent---you get the same result if you do it once, twice, or a hundred times.
But actually, if $k is tied, fetching might not be idempotent. You might fetch twice and get different values both times. Fetching might call a function that prints something on the console, or that halts the program on the 57th fetch. Anything could happen.
Similarly, our nifty ?...? optimization breaks in the presence of tie. We optimized away fetches on the elements of @numbers, and most of the time that is OK. But if @numbers is tied, that might drastically alter the meaning of the program, which is just what an optimization must never do.
The authors of C compilers have this same problem. They call the problem volatile. A volatile object is just like a tied variable in Perl; it might have arbitrarily weird fetch or store semantics. volatile objects defeat optimization. However, in C, volatile objects must be declared in advance, at compile-time, and the compiler can assume that any variable not so delcared is not volatile. Perl has no such guarantee; there's no way to tell at compile time whether a given variable will be tied or not.
The only alternative is to put the burden on the programmer. That is a pain, because you might count on your tied variable being fetched a hundred times, but unbeknownst to you the optimizer has removed it from the loop.
Sorry, no conclusion today.
print "\L\u$word";
Back in 1996, I needed to write a program that would print out something or other in all lowercase, with an initial capital letter. It was coming out of the database in all capitals. I could have used this:
print ucfirst(lc($word)), "\n";
But for compactness I wanted to use the equivalent \L and \u string escapes. The equivalent expression would have been:
print "\u\L$word";
But for some reason I decided to write it backwards. (I don't think I did it by mistake, although that is a possibility.) I wrote a test program to print out this instead:
print "\L\u$word";
I expected it to print in all lowercase, but it didn't. It printed with an initial capital. I was really startled. I sent mail to the perl5-porters mailing list:
: I had a program in which a variable contained a town name in all caps. : I wanted to capitalize only the first letter when I interpolated it : into a double-quoted string. : : I tried : : \L\u$town_name\E : : which I knew wouldn't work, but it *did* work---I got the town name in : lowercase with initial capital letter.
Here was Larry's reply:
# Fancy that. :-)
This was actually a feature: The Perl lexer looks to see if you wrote \u\L or \l\U in the `wrong' order, and if you did, it switches them for you. Here's the code. In version 5.005_02, it's around line 1595 of toke.c:
if (strnEQ(s, "L\\u", 3) || strnEQ(s, "U\\l", 3))
tmp = *s, *s = s[2], s[2] = tmp; /* misordered... */
One thing that has struck me over and over again in year of reading p5p is how almost everyone on the list is a lot more conservative than Larry. I can't remember the exact circumstances in which this first occurred to me, but there was some problem people were discussing and Larry suggested solving it with a special sort of boolean value that would yield false the first time it was tested but would become true thereafter.* Everyone was speechless. If anyone else had made such a suggestion, they would have been ridiculed. That option isn't available when it's Larry's suggestion, so nobody knew what to say. But Larry comes up with stuff like that all the time.
It was Larry's idea to special-case "\L\u". I don't think anyone else would have thought it was a good idea if they had thought it up themselves. I don't want to argue about whether it was a good idea or not; I just want to point out that Larry made a lot of other similarly weird decisions and the result was Perl, which is a huge success.
Every time Larry has an interview, he talks about how academic language designers always want `orthogonality', so that every feature works like every other feature, and there are no funny exceptions or shortcuts, and how he designed Perl to be diagonal instead of orthogonal. But orthogonality seems to be very important to the people on P5P now. This could be for several reasons: Part of it I think is that people see that Perl is growing up and maturing and they want it to have a wider appeal and to shed some of its reputation for bizarreness. Partly I think it's just that they don't have as much imagination as Larry. And partly I think it's that designing good diagonal features is very difficult, or at least poorly-understood, and people don't trust themselves to get it right. They think that Larry has some magical power to find the bizarre exceptions that are safe, and that if someone else tries, it'll be a disaster. Of course, this might be correct.
But it still seems like a shame not to try. The world is already full of orthogonal languages. Perl was a great experiment in diagonality, and it was a big success. I worry that it doesn't make sense to abandon that philosophy in its moment of triumph.
s{(.*?)(\`([^\']*)\')}
{$pos += length $1;
my $length = length $2;
print ((' ' x ($pos)), "^", (' ' x ($length-2)), "^ ? ");
my $r = lc <STDIN>;
$pos += $length;
(substr($r,0,1) eq 'n') ? $& : "$1<tt>$3</tt>"
}eg;
Continued from yesterday.
Usually I like to run the LOD into one long line, and show the split-up version later on, but this was was Just Too Big.
Yesterday I had a really nice solution to the problem of querying the user for each of several possible substitutions in a line, and performing only the specified substitutions. The code was really simple, and depended on a rather bizarre trick: The code to read the user's response was embedded in the substitution part of a s{}{}ge expression. It was much shorter and simpler than the other way I showed. But it suffered from a drawback: The original version used pos($_) to figure out where in the original string the current substitution was taking place, and to underline the string that would be substituted. With the s{}{}ge solution, this doesn't work, because s{}{} doesn't set pos(). So we have to look for something else.
s{}{} doesn't set pos(), but it does set $1, $2, and soforth. If we can caputure the characters between the pervious and current match, and count them, and keep a running total, we'll know how far into the string we are. This is what this Line is about.
The pattern match has changed from just \`([^\']*)\', which is the pattern we really want to identify, to (.*?)(\`([^\']*)\'), which has some extra machinery to load things into $1 etc. The (.*?) on the front gathers up all the characters from the end of the pervious `...' up to the beginning of the current one and stores it into $1. If we keep a running total of the length of the $1's, we'll have the total amount of space between quoted items. If we add the lengths of the quoted items, we'll know how far along into the string we are.
The variable $pos tracks this. After matching the pattern, we add in length $1, which is the length of the interpattern space since the last `...' item; then we use $pos the way we used pos($_) in earlier examples.
We also used $& for prompting before, and we need it here not just to know how much to underline but also because we have to add it to $pos to bring $pos up to the end of the current match. But since we've added extra stuff to our regex, $& is no longer just the quoted item. So we'll wrap the whole quoted item in another pair of parentheses and use $2 instead of $&. The line my $length = length $2; corresponds to the earlier versions' $length = length $&. The actual prompt string,
((' ' x $pos), "^", (' ' x ($length-2)), "^ ? ");
is completely analogous to the prompt string from the earlier examples:
((' ' x $end-$length), "^", ('-' x ($length-2)), "^ ? ");
We even get a small win from managing $pos ourselves: The real pos() goes all the way to the end of the match, and we have to subtract $length from it to find the place that's at the beginning of the match. But when we manage it ourself, we can postpone adding in the $length until after we've generated the prompt.
There's one final subtle point here: The regex has to begin with (.*?) and not with (.*). This is because (.*) is greedy, and will gobble up all the characters to the last occurrence of `...', and we'll only be prompted to change that one. By using the non-greedy (.*?) regex, we simulate the normal behavior of the regex, which is to move left to right one character at a time until it finds a matching occurrence.
s{\`([^\']*)\'}{print " $&\n"; my $r = lc <STDIN>; (substr($r,0,1) eq 'n') ? $& : "<tt>$1</tt>"}eg;
Continued from yesterday.
After a lot of messing around with m//g and substr and so on, I had a bright idea: You can use s{}{} to do a conditional substitution of you put the condition inside the subtitution part and evaluate it with the /e option. It's a lot easier to see what's going on if the code has proper white space:
s{\`([^\']*)\'}
{print " $& ";
my $r = lc <STDIN>;
(substr($r,0,1) eq 'n') ? $& : "<tt>$1</tt>"
}eg;
The /e on the end means that the second part of the substitution is code, which could be evaluated, and that the resulting value should be used to replace the matched `...' string. The code is straightforward: We print a prompt, which consists of the string that we're about to replace, which is in $&. Then we get an input from the user, as before. If the input begins with n, we return the original matched string, which is in $&; otherwise we construct and return the changed version of the string, which looks like "<tt>$1</tt>".
The s{}{} part looks a lot worse, but it's still a good tradeoff, because most of the rest of the program, including the the m//g and its attendant while loop, and also everything having to do with @todo, just go away. Here's the entire program:
while (<F>) {
print;
s{\`([^\']*)\'}
{my $r = lc <STDIN>;
$pos += $length;
(substr($r,0,1) eq 'n') ? $& : "<tt>$1</tt>"
}eg;
print OUT;
}
This is only about half as long as yesterday's version.
If we want to put in fancy prompting like I showed yesterday, however, there's a problem: We can't use pos(), because s{}{} doesn't set pos(). I'll show how to solve this problem tomorrow.
print ((' ' x $end-$length), "^", ('-' x ($length-2)), "^ ? ");
Continued from yesterday.
I was trying to make a program which would locate certain patterns in the input, prompt me about each one, and, if I answered in the affrimative, replace each one with a replacement string. I have a partial solution from yesterday:
while (<F>) {
while (m/`[^']*'/g) {
my ($end, $length) = (pos($_), length $&);
my $r = lc <STDIN>;
if (substr($r, 0, 1) ne 'n') {
substr($_, $end-$length, $length) =~
s{`([^']*)'}
{<tt>$1</tt>};
}
}
print OUT;
}
This has a problem: If you say `no' to one of the prompts and `yes' to a later one, it goes back and asks you about the `no' instances again. This is because saying `yes' tells Perl to do the s{}{}, which modifies $_, which reseats the position of the m//g. It starts over at the beginning and sees the unmodified occurrences again.
The solution here is to postpone the substitutions until all the questions are finished, and then to do them all at once. Instead of performing the substitutions immediately, we push them onto a list; the list will contain instructions about the substitutions we do want to make. After we've asked the questions, we go through the list of changes and make them all at once:
while (<F>) {
my @todo;
while (m/`[^']*'/g) {
my ($end, $length) = (pos($_), length $&);
my $r = lc <STDIN>;
if (substr($r, 0, 1) ne 'n') {
push @todo, $end-$length, $length;
}
}
while (@todo) {
my $length = pop @todo; my $start = pop @todo;
substr($_, $start, $length) =~
s{`([^']*)'}
{<tt>$1</tt>};
}
print OUT;
}
There's one subtlety here: We go through the @todo list in reverse order. Why? Suppose the original string is `1' `23', and we want to change both instances of `n'. @todo will contain two pairs of numbers: 0,3 and 4,4. If we went through these in forward order, we would do the 0,3 pair first, which turns the string into <tt>1</tt> `23'. Then we would try do do the substitution at position 4. But the contents of position 4 have changed! They're not `23' any more; they're now 1<tt. By doing the substitutions starting at the end, we always leave the beginning untouched, so that the positions of the earlier substitutions don't change.
Now it was working, so I added prompts:
while (<F>) {
my @todo;
print;
while (m/`[^']*'/g) {
my ($end, $length) = (pos($_), length $&);
print ((' ' x $end-$length), "^", ('-' x ($length-2)), "^ ? ");
my $r = lc <STDIN>;
if (substr($r, 0, 1) ne 'n') {
push @todo, $end-$length, $length;
}
}
while (@todo) {
my $length = pop @todo; my $start = pop @todo;
substr($_, $start, $length) =~
s{`([^']*)'}
{<tt>$1</tt>};
}
print OUT;
}
Now if the input looks like this:
We will call him `Clark'. `In that case,' he said, `I should drink it.'
The program will emit prompts like this:
We will call him `Clark'.
^-----^ ?
`In that case,' he said, `I should drink it.'
^-------------^ ?
^------------------^ ?
The ? indicate places where the program waits for user response.
After I had this working, I figured out a much simpler way to do the same thing. Nevertheless, I think that this technique of restricting a substitution to occur in just a matched substring is probably useful in general. I'll show the simpler method tomorrow.
my ($e, $l) = (pos($_), length $&);
I recently needed to solve a straightforward-sounding puzzle: I had a file, which contained many occurrences of `quoted text'. I wanted to change some, but not all, of these occurrences to <tt>tagged text</tt> instead, and I wanted to be prompted for each one and say yes or no to it. This is similar to the s///gc feature of the vi editor.
It turned out to be much more difficult than I had thought it would be. The basic problem is this: Suppose the string you're operating on contains three occurrences of the pattern, and you want to replace the first and third of these. After you decline to replace the second, you have to make sure that your matching process doesn't pick it up again and ask you over and over if you don't want to change it after all. Some wrong answers will do this immediately, refusing to go on to the third occurrence until you give in and agree to replace the second one, and some wrong answers will return to the second occurrence after asking about the third one.
For example, the first thing I thought of looked something like this:
while (<F>) {
while (m/`[^']*'/g) {
my $r = lc <STDIN>;
if (substr($r, 0, 1) ne 'n') {
s{`([^']*)'}
{<tt>$1</tt>};
}
}
print OUT;
}
This obviously doesn't work, because if the string is `1' `2' `3' and you say yes-no-yes, then after the `no' the string is <tt>1</tt> `2' `3' and on the second `yes', which you want to change the 3, the s{}{} replaces the quotes around the 2 instead of around the 3. So this is no good at all. That's where the Line of the Day comes in. Instead of the code above, I used this:
while (<F>) {
while (m/`[^']*'/g) {
my ($end, $length) = (pos($_), length $&);
my $r = lc <STDIN>;
if (substr($r, 0, 1) ne 'n') {
substr($_, $end-$length, $length) =~
s{`([^']*)'}
{<tt>$1</tt>};
}
}
print OUT;
}
We only want the s{}{} to operate on the matched part of the string. This part is stored in $&, so its length is length $&. It ends at pos($_), which is the same as the place that the next regex match on $_ will start looking. From these two facts we can deduce that it begins at position length($&)-pos($_). In development versions of Perl after 5.005, we could have used the new special variables $-[0] and $+[0] instead.
Anyway, having figured out exactly where in $_ the matched sequence lies, we then confine the s{}{} to operate on just that substring of $_.
This still suffers from the problem I mentioned before. If your string has multiple occurrences of `quoted text', and you decline to substitute one, then after doind a substitution, the program will come back and ask you about the declined one again. This is a pain. Tomorrow I'll show how I fixed it, and then on Wednesday I'll show a totally different solution that is much simpler.
sub Rebind::TIEHASH { $_[1] }
Roland Giersig raised an interesting problem a while ago. He had a tied hash, tied to a Tie::IxHash object, and he wanted to freeze it to disk and reinstate it later. He could use Data::Dumper to freeze the underlying object, and reinstate it, but the connection to the hash itself wasn't reinstated; only the object. Roland wanted to know how to reassociate the object with the hash variable.
Normally the way you associate an object with a hash variable is with the tie function. You say tie %hash => Package, and that calls the TIEHASH method in the package. The TIEHASH method is supposed to construct an object, which Perl then associates with the hash variable. Roland's problem was that Tie::IxHash::TIEHASH would construct a new object, whereas he had this old reinstated object that he wanted to be used instead.
One solution I suggested was to make a subclass of Tie::IxHash to implement a new constructor that takes an old Tie::IxHash object and uses it to build a new object which inherits all its methods, including FETCH and STORE, from Tie::IxHash. But then I realized that the construction process could be simplified: All it would be doing is copying all the innards of the original object, so why not just re-bless the original object itself?
But then I realized there was no need to do the re-blessing. Just have the subclass constructor return the old object without changing it at all! Perl doesn't care that the object rturned by the subclass constructor is a Tie::IxHash object rather than a subclass object.
If you do it that way, you not only don't have to tamper with the object at all, but you don't waste CPU time searching for inherited object methods---the object is in the Tie::IxHash class, not in the subclass, so it doesn't have to inherit. And since the subclass won't ever contain any objects, and no methods will ever be inerited, you needn't even set @ISA. The `subclass' is a null subclass that doesn't inherit and which constructs objects from some other class. But when you tie an object into this dummy class, it comes out tied to a hash variable.
Let's call this dummy class Rebind. You can use Rebind to associate any object with any variable. For example, suppose you have some tied hash class X, and for some reason you want to tie three hashes into this class but have them all be served by the same underlying object. No matter how X is defined, you can do it this way:
use X;
sub Rebind::TIEHASH { $_[1] }
my $x = tie %a => X, arguments;
tie %b => Rebind, $x;
tie %c => Rebind, $x;
Here, %a, %b, and %c have all been tied to package X, and stores or fetches on any of them will be turned into method calls on the same object, $x. Or you can use $x imlpicitly if you like:
use X;
sub Rebind::TIEHASH { $_[1] }
tie %a => X, arguments;
tie %b => Rebind, tied %a;
tie %c => Rebind, tied %a;
I expect that this will turn out to be really useful, but I can't think of any useful uses of it offhand except for Roland's use. But watch this page for further developments.
$lexer = '((?s)'
. (join '|',
map {quotemeta(pack 'S', $_) . ('..' x $opn[$_]) }
(0.. $#opn)
)
. ')';
Oh, gosh, it's Yet Another Lexer.
I just can't stay away from lexers. The wonderfulness of writing a complete lexer in a single regex never wears thin for me.
This time the language I needed to lex was bytecode, compiled from a special-purpose language that I won't describe. The bytecode was a sequence of instructions; each instruction had a two-byte opcode followed up to three two-byte operands. Here's a sample program in the original source code format:
SAY Blank
RANDOM I 100
ITOBJ I
APPORT I Limbo
EOI
This sample program was represented by the following bytecode stream:
51 7001 50 11006 100 36 11006 3 11006 4241 16
51 is the opcode for SAY; 7001 is a code for the string Blank; 50 is the opcode for RANDOM; 11006 is a code for the variable I; and soforth. You can see the other occurrences of I popping up in the rest of the bytecode.
Actually the byte code was written into a binary file as a sequence of two-byte integers. When Perl read some bytecode from the file, it got a string like this:
"3\0Y\e2\0\376*d\0$\0\376*\cC\0\376*\221\cP\cP\0"
The 3\0 is actually the 51 that encodes SAY, because the charater 3 has ASCII code 51. The \376*'s that you see are encoding the various appearances of the variable I.
I wanted to take a string like this and break it up into a list of instructions. I realized that I could do it with a lexer regex like this one:
m/(
\x33\x00 .. # \x33\x00 is the opcode for SAY, followed by one operand
| \x32\x00 .. .. # \x32\x00 is the opcode for RANDOM, followed by two operands
| \x24\x00 .. # \x24\x00 is the opcode for ITOBJ, followed by one operand
| \x03\x00 .. .. # \x03\x00 is the opcode for APPORT, followed by two operands
| \x10\x00 # \x10\x00 is the opcode for EOI, followed by no operands
| (other alternatives for the other 53 opcodes)
)/xg;
This is similar to the other lexers I've showed here before on 18 April 1998 and 8 April 1998, so I won't explain this in detail.
Now I needed to construct the lexer regex itself. I had an array, @opn, which held the number of operands needed by each opcode. For example, $opn[51] contained 1 because 51 is the opcode for SAY which requires one operand. For each opcode, from 0 to 57, I needed to construct an alternative that would match the opcode (as a packed two-byte number), followed by one occurrence of .. for each permitted operand. That's just what this does, If $_ holds the opcode number:
quotemeta(pack 'S', $_) . ('..' x $opn[$_])
I need the quotemeta there because if the opcode is 42, it'll turn into "*\0", and the * will be taken as a request to repeat the previous byte many times, which is certainly not what we want.
Now I wrapped up this expression in a map that generated the list of all the alternatives, one for each possible opcode:
map {quotemeta(pack 'S', $_) . ('..' x $opn[$_]) } (0.. $#opn))
Finally, I turned this list into the regex I want by joining the alternatives together with | in between, and slapping ( on the front and ) on the end. Actually I also inserted a (?s) in there; that tells the regex engine that it is OK to let the . symbols match newline characters if there happen to be any in the bytecode.
I actually used the lexer expression as part of a loop like this:
while ($code =~ /$lexer/og) {
my ($op, @args) = unpack "S*", $1;
push @instr, [$opname[$op], @args];
}
Each call to the regex extracts exactly one instruction from the bytecode sequence and deposits it into $1. When I unpack $1 as a list of shorts, the first item is the operator itself and the remaining shorts, if any, are the operands. I use an array @opname to replace the opcodes with operator names like SAY. If $code is the Perl string "3\0Y\e2\0\376*d\0$\0\376*\cC\0\376*\221\cP\cP\0", the result of running this loop is the following Perl structure:
(['SAY', 7000], ['RANDOM', 11006, 100], ['ITOBJ', 11006], ['APPORT', 11006, 4241], ['EOI'], )
The thing was a huge success. It was efficient and it worked on the second try. (The first try omitted the (?s).) It's also easy to modify---if I change the @opn table, the lexer changes automatically to match.
The S in the pack function means to use my machine's short int format, which has the less significant byte first. If you try this out at home you may want to use v instead or you may get different results.
The original version had '.' x (2*$opn[$_]) instead of '..' x $opn[$_] because it was very late at night when I wrote it.
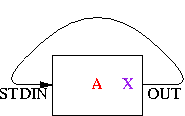
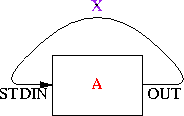
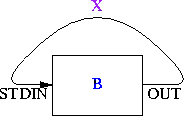
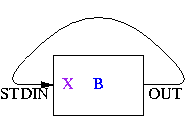
pipe(STDIN, OUT) or die "pipe: $!";
A couple of weeks ago I had what seemed like a very clever idea, and this line is the key part of it. Here's the complete idea:
# `The Secret Passage' close STDIN or die "close STDIN: $!"; pipe(STDIN, OUT) or die "pipe: $!"; print OUT "Secret password!"; close OUT; exec "command"; die "exec: $!";
Here's the problem this is intended solve: Program A knows some secret information X, such as a password, which it needs to pass to program B somehow. It should not pass X to B as a command-line argument, because command-line arguments are usually visible with the ps command, and X must remain a secret. Similarly, passing X as an environment variable is insecure.
One way to do it is for A to spawn a child process to which it is connected by a pipe. The child process execs B, and A sends X to B through the pipe. This is secure.
But one plausible scenario is that A is going to exit immediately after closing the pipe. For example, A might be a setuid program that uses its privileges get get X from somewhere; then it will change its uid to one with lower permissions and run B; A wants B to get X but not have any of the other privileges of the original uid. In this case, A does not need to hang around after running B and writing X into the pipe, because its work is done, so it can exit immedately. In such a case the fork is wasted.
The code above is the strategy that A can use. It writes the data through a pipe to the child process---except that there is no child process. X goes into the pipe and stays there. Then A execs B. The reading end of the pipe is attached to B's standard input, so B can read X directly. Everything in A's memory was destroyed in the exec, but X was not in A's memory; it was in the pipe.
|
|
|
|
| A creates a pipe to itself | A writes X into the pipe | A execs B | B reads X from STDIN |
I've never seen this trick before, so I've decided to name it `The Secret Passage'. Sample demonstration programs are available in Perl and in C.
Note added 20 June: Brian Matthews informs me that he anticipated this idea by about thirteen years, and in fact used it for the same purpose that I originally suggested for it. Now is the time when I get to congratulate myself for not trying to name the Device after myself.
(reverse $str) =~ /^(?!oof)/;
Continued from yesterday.
Again, the problem is to write a regex that matches any string that does not end in foo.
Here's we've moved out of the realm of pure regexes into allowing external constructions like reverse as well. That makes this solution ridiculous, because if you aren't restricted to simple regex matches, the obvious solution is simpler and faster:
$str !~ /foo$/;
But it's interesting that in this case, the reverse solution is fast enough to beat out all the simple-regex contenders. I keep looking for a place to use it, and so far I haven't found one. Someday I will, and that'll be a fine hack.
/^(?!.*foo$)/
Continued from yesterday.
Again, the problem is to write a regex that matches any string that does not end in foo.
This one is actually the winner. It works, and it's fast. And it's also the simplest! It uses something of a sly trick, however: You thought there was no way to negate a regular expression, but there is: (?!...) makes a recursive call to the regex matcher and asks if what follows in the string will match the ... part; if so, it fails; if not, the (?!...) matches the empty string. So it really does negate; it looks to see if there's any way to locate foo at the end of the string, and if so, it fails at that point.
There are a couple of subtleties here. First, why doesn't it exhibit the bad backtracking behavior that the others did, trying every possible length for the .*, even lengths that don't reach to the end of the string and cause the $ to fail? It would, except that the regex engine has an optimization that kicks in: When the expression that precedes the $ is simple enough, it is smart enough to avoid that error. .*foo is simple enough; the complicated stuff from previous Lines of the Day was too complicated to permit the optimization.
The other subtlety is the ^. What happens if we omit it? In that case, the regex engine tries the (?!.*foo$) at every position, looking for a place that .*foo$ won't match, instead of just at the beginning. But if it's allowed to look anywhere, it can always find a place where .*foo$ won't match: At the very end of the string, after the last character. Or to take a slightly less degenerate example, consider the string Barfoo. If matching starts just after the f, then .*foo$ will fail and (?!.*foo$) will succeed. So you need the ^ there or else the regex will match any string.
There's a moral here. The moral is: Simpler regexes can be faster, because complicated ones defeat the common-case optimizations in the regex engine.
Tomorrow we'll see some faster solutions that are even simpler.
/((?!foo)...|^.{0,2})$/
Continued from yesterday.
Again, the problem is to write a regex that matches any string that does not end in foo.
This is another try with a different strategy which unfortunately combines the worst features of the ones from June 5 and June 3. The (?!foo)... first looks to see that the next three characters are not foo, and if so it matches the three characters, which must be at the end of the string, because of the following $. Unfortunately, the regex engine doesn't just look for this pattern at the end; it looks for it everywhere from the start to the end, each time failing when it realizes that it isn't long enough to reach the end.The ^.{0,2} is just a special case to match strings that are too short to be matched by ...$.
/^(|.|..|.*[^f]..|.*f[^o].|.*fo[^o])$/
Continued from yesterday.
Here's another shot at the same thing: A regex to match all strings that don't end in foo.
This is an application of a general strategy that is sometimes useful. Suppose you want to match all strings that do not contain the letter n. That's very easy, of course:
/^[^n]*$/
No suppose you want to match strings that don't contain the word no. You can only negate characters, not words, but that's OK. The characters in this string are now allowed to be n's, but if they are they must not be followed by o's:
/^([^n]|n[^o])*$/
This actually isn't quite right because it requires that each n be follwed by something that is not an o, and it should be requiring that each n is not followed by an o, which is slightly different. But for the example we're really trying to look at, of matching strings that don't end in some forbidden string, there is no difference.
If we wanted to forbid the appearance of the word not we could do a similar thing: n's may not be followed by o's, unless the o is not followed by t:
/^([^n]|n[^o]|no[^t])*$/
The principle in the regex is the same. The first three cases expressly allow strings of lengths 0, 1, and 2, since these strings cannot possibly end with foo. The fourth case allows all strings where the third character from the end is not an f; such a string can't end in foo. The fifth case says that actually the third character from the end can be an f as long as it's not followed by an o; the last case says that actually it's OK for the f to be followed by an o as long as the o is not followed by another o.
Unfortunately, the regex engine is not smart enough here, and this pattern is even slower than the June 3 pattern. In the fourth alternative, for example, it tries making the .* every possible length, even when this obviously won't work. For example, suppose the string is Dominus. One alternative that the regex engire tries is letting the .* match just Do; then the next character is not an f, the following two characters can be anything, and then it realizes that it should be at the end of the string (because of $) but it isn't. So it backs up and tries again---and this time it lets the .* match just the D, and it falls even shorter of the end. In a long string, it wastes a lot of time by making the .* too short in many different ways. Then it repeats the same series of mistakes in cases 5 and 6. At present there is no way to fix this.
/^(?:(?!foo$).)*$/
This is out of the Ram book. It's the answer to the question ``How do you match strings that don't end with foo?''
Unfortunately, this isn't a very good answer. To see why, let's see how it works.
The (?!foo$) means to check ahaead from the current position and see if the string ends with foo at the current position. If not, the following . tells the regex matcher to move to the next position, and the * sends it back to try the same thing again. It goes through the string one position at a time, starting at the beginning, checking to see if it is at foo anat the end of the string, and moving forward one position if not. This means that if the string has length 1000, it will check 1000 times for foo.
This is clearly wasteful---there's no need to keep looking ahead for foo until the end. Over the next few days I'll show several different solutions to this same problem. You might like to try solving it yourself and see what you come up with.
++vec($_[0], 1, 32) or ++vec($_[0], 0, 32);
When I was writing Tie::HashHistory I needed to have a counter that would serve as a version ID number for different versions of the value associated with a key. I was going to be storing the version number in the same space as the associated value, so I needed a way to separate it from the actual value. The two choices here, as always, were: Use a special separator character (so that values would look like 012345:value) or use a fixed-size version number (so that the values would look like XXXXvalue). For convenience and speed, I chose the latter. I would represent strings as packed binary numbers. The first version number would be "\x00\x00\x00\x00", the second would be "\x00\x00\x00\01", and so on up to "\xff\xff\xff\ff".
That raised the question about how to manage such numbers. One strategy that suggested itself immediately was to use pack and unpack. I could unpack the 4-character string into a Perl integer, increment it, and pack it again. That seemed like a lot of work for something that should just be a single machine instruction, so I looked for something more efficient that would manipulate the string directly. Chris Nandor suggested looking to vec() and it turned out the be just the right thing:
++vec($string, 0, 32);
did exactly what I had wanted.
But then I worried that 32 bits would not be big enough. If the version numbers overflowed over, the package would break and return the wrong values---you might ask for $hash{x} and instead get some ancient value for $hash{y}. 32 bits of numbers is only four billion versions. If you change a hundred keys a second, you will run out of version numbers in sixteen and a half months. The plausibility-imminence quotient seemed pretty large, so I decided to investigate 64-bit version numbers. With 64-bit version numbers you won't run out for 584 years even if you make a billion changes a second.
It was easy to use an eight-character string instead of a four-character string, of course, but the increment logic became more complicated. I would have liked to use this:
++vec($string, 0, 64);
But vec() does not accept a third argument any larger than 32, because Perl is expecting to be on a system with 32-bit native integers. So I would have to arrange to increment the low word and handle overflow there and carry if appropriate.
My first cut at it looked like this:
sub _increment {
if (vec($_[0], 1, 32) eq "\xff\xff\xff\xff") {
# Handle carry
vec($_[0], 1, 32) = "\x00\x00\x00\x00"; # Reset low word
vec($_[0], 0, 32)++; # Increment high word
} else {
vec($_[0], 1, 32)++; # Increment low word
}
}
This worked, but then Randal Schwartz pointed out that there is a better way to write it. If you try to increment "\xff\xff\xff\xff", it rolls over to "\x00\x00\x00\x00". Since this is the value you want it to have anyway, the explicit assignment of "\x00\x00\x00\x00" is a waste of code. It's easier to write:
++vec($_[0], 1, 32) or ++vec($_[0], 0, 32);
We increment the low word, and if it has rolled over to zero, we carry over to the high word. This is slightly miraculous, because even though the ++ modifies the packed string, the return value of the expression is a Perl number, suitable for use with or.
Randal also suggested replacing postfix ++ with prefix, which is faster because it doesn't have to save the old value for later.
Now that the subroutine was down to one line, I just inlined it into the places that used it to avoid the function-call overhead.
* Note added 20020306: I've been thinking this even longer than I realized. Tom Christiansen preserved a rambling monologue on this same topic that I delivered on IRC in 1997. I seem to recall that it was late at night (or early in the morning) and that I thought nobody was listening. You can find it here.
Return to: Universe of Discourse main page | What's new page | Perl Paraphernalia | Line of the Day