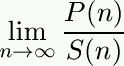
© Copyright 1999 M-J Dominus.

This paper will attempt to get a sense of how difficult it is to write computer program in various languages. We develop a model of a computer programmer and estimate the likelihood of the programmer developing a syntactically correct program.
Experience in industry suggests that the likelihood of a programmer coming up with a working program is vanishingly small. For most computer languages, such as C or Lisp, this intuition is correct. However, Perl is unlike most other languages in this regard.
Suppose for concreteness that programs are written in the ASCII character set, which has 128 characters. Let S(n) be the number of ASCII strings of length n, and let P(n) be the number of syntactically correct programs of length n. Then the likelihood of the programmer developing a syntactically correct program of length n at random (which is well-known to be the most common method of software development) is:
At first glance, you would expect that this limit would be zero. For most languages, such as Lisp, this is the case. This is because in Lisp, a syntactically correct program must have balanced parentheses, and the probability that a string that contains n pairs of parentheses is well-formed is proportional to 1/n. (There are some complications, of course; for example, parentheses that occur inside of Lisp comments or literal strings need not be balanced. But these turn out not to affect the result, and this is a paper about Perl, so I will leave the details as an exercise for the reader.) A similar argument applies to C programs.
In Perl, however, this limit is not zero. This can be seen as follows: If the first eight characters of the program are __END__\n, then the program will always be syntactically correct, regardless of what the following n-8 characters are. Therefore, among strings of length n, at least 2-56 of these are syntactically correct Perl programs, for any n whatsoever. This demonstrates that the limit above, if it exists, is no smaller than 2-56.
Substantial improvements to this lower bound are possible. Noting that Perl programs can also include the sequence __DATA__\n, we can increase the lower bound to 2-56 + 2-63. Another example: If w is any sequence of whitespace characters (space, tab, carriage return, newline, and form feed), and s is any string, then w__END__\ns is a syntactically correct program of length |w| + 8 + |s|. There are 5|w|128|s| such strings out of 128|w|+8+|s|. The total likelihood of selecting one of these at random is therefore:
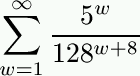
Which is equal to 5/(123×256), or approximately 2-60.62.
Obviously, a more nearly complete enumeration of syntactically correct programs would raise the lower bound still further.
It is tempting to try to apply this argument to other languages. One might want to say that any C program that begins with /* and ends with */ will be syntactically correct, but this is not the case, because there is an additional restriction: The intervening characters must not contain another occurrence of the */ sequence. But as n becomes arbitrarily large, nearly all random strings do contain an extra */ in the middle, and so the likelihood of getting a C program that is one huge comment approaches zero.
Conclusion: Strings selected at random are much more likely to be syntactically correct Perl programs than they are to be C or Lisp programs, and in fact have positive probability of being correct. This should give comfort to beginning programmers struggling with Perl syntax; it really is easier to write a syntactically correct program in Perl than in most other languages.
(2001-03-21) Stephen Turnbull pointed out that my assertion about Lisp misses an important point about Lisp. A Lisp programmer who wanted to generate code at random would never generate a random string. Instead, they would generate a random list structure; questions of syntax would then become moot.
This does throw light on an important difference between Perl and Lisp. Perl programmers are concerned with strings and with string data; Lisp programmers use structured data wherever possible. This is a much more robust and powerful approach, and nobody should discount it. The rest of the world is only beginning to discover the benefits of the Lisp way of doing things---this approach is precisely what XML is about.
Nevertheless, I think it isn't germane to my paper. The paper is about the likelihood of a beginning programmer generating a syntactically correct program by doing what beginner programmers always do---that is, by pounding on the keyboard. Beginning Lisp programmers do not write clever Lisp programs to generate code at random; they pound on they keyboard just like everyone else. So I think my conclusion still stands.
My thanks to Mr. Turnbull for his thought-provoking remarks.

Return to: Universe of Discourse main page | What's new page | Perl Paraphernalia