

<BOAST>This paper, and the package it describes, won the 2001 Larry Wall Award for Practical Utility.</BOAST>
Some time late in 1998 or early in 1999 I used the (?{...})
construction to embed a print statement inside the regex:
"abcbbcbbbc:" =~ qr/(\w*)([bc]{7,})(?{print "$1 $2\n"})$/
This produces the following output:
abc bbcbbbc
ab cbbcbbbc
ab cbbcbbb
a bcbbcbbbc
a bcbbcbbb
a bcbbcbb
bc bbcbbbc
b cbbcbbbc
b cbbcbbb
bcbbcbbbc
bcbbcbbb
bcbbcbb
c bbcbbbc
cbbcbbbc
cbbcbbb
bbcbbbc
As you can see, the greedy \w* first tries to eat up as much as
possible, but the regex can't proceed until the \w* backs off
enough to let the [bc]{7,} eat seven more characters. The ':'
in the target string prevents the regex from matching, and each time
the engine backtracks, we see another line of output.
At the time, this didn't work with the stable version of Perl, which
was 5.005_03, because the backreference data wasn't copied soon enough
for print to get hold of it. I had to run it under 5.005_53.
I was sufficiently pleased by this that I sent mail to Jeffrey Friedl about it. That mail (from May 1999) is the earliest record I can find of my investigation of the idea, but by then I had already developed it rather far. A related example I brought up:
"abbbbbbbbb" =~ qr/(\w*)
(?{print "--$1\n"})
(b{7,})
(?{print " $2\n"})$
/x;
If you run this and look at the output, you can see that the \w*
eats up too much at first, and has to back off so that the b{7,}
part has something to match. I also mentioned:
(?!) on the end you can force it to backtrack through
all possible alternatives in order; this shows what m//g would
produce if you were to use m//g...
I also realized soon after that this technique would make it possible to build a regex debugger that supported breakpoints, watches, step-by-step execution, and so forth. I have a note (unfortunately undated, but definitely prior to July 1999) in my notes file that says
(?{print $1})
and the like, instrument them with
(?{foo($`,$&, $')})
or some such, where foo is a function that updates the state of the regex in a Tk window. If the function waits for a button press before continuing, you have a regex debugger.
Since this is probably one of the best ideas I've had in the past three years, I wish I could take the credit for it. But I can't:
http://www.xray.mpe.mpg.de/mailing-lists/perl5-porters/1998-10/msg00957.html
From: larry@wall.org (Larry Wall)
To: ilya@math.ohio-state.edu (Ilya Zakharevich)
Cc: perl5-porters@perl.org (Mailing list Perl5)
Date: Fri, 16 Oct 1998 17:40:23 -0700
Message-Id: <[12]199810170040.RAA08472@wall.org>
Y'know, if we temporarily set curpm during a ?{expr} to the
current pm, we could have
'ABCBD' =~ /(B.*)(?{ print "$1\n" })(?!)/
print out all the possible ways that B.* (or whatever) could
match, as is being asked for currently in clpm.
I don't remember reading this, but I almost certainly did read it---whether before or after I had the idea myself, I don't know.
In early August of 1999 I had a working graphical regex debugger as a
proof-of-concept. I already know that the (?{...}) instrument idea
would work, so I put most of my effort into the Tk front end. Figure
1 shows the proof-of-concept application just after startup. Figure 2
shows it in the middle of a run; it is matching the string
seventeenth against the regex e*nt. The display shows that
e* part has matched the ee; the n has matched the following
n, and the t part has matched the following t. The display
previously showed other matches, including sev<ent>eenth
and seve<nt>eenth. You can't see it in the picture, but
eent is presently red, indicating an incomplete match; clicking
Next once will cause the eent to turn green, to show that the
regex has succeeded. Clicking a few more times will cause the
debugger to step along and find more matches such as
sevente<ent>h and seventee<nt>h.
Tk turned out to have an impedance mismatch for what I wanted to do.
I wanted the Perl regex engine to run continuously, and to call my
callback when it reached a (?{...}) instrument. The callback would
then update the Tk window and then wait until the user clicked a
button in the window, whereupon it would return control to Perl
There is no way to do this directly with Tk or to ask Tk for a notification when a button is clicked. In a Tk application, when you click a button or other control, a callback function is invoked; returning from the button callback returns to the Tk main loop, but there is no way to return from the main loop to the program that invoked it.
Clinton Pierce offered a clever solution, which seems of sufficiently general utility that I will describe it in detail. The regex engine was run in one process, and invoked the instruments. The Tk interface was in a child process, connected to the parent by a pair of pipes.
Initially, the Tk window just displayed a message saying that it was ready to go. There was a 'Next' button. Tk waited around for the user to click the button. Meanwhile, in the background, the parent process was running the regex.
When the regex engine reached an instrument, it called a pause()
function back in the parent. The pause() function sent information
to the Tk process containing the values of $&, $1, and so forth,
and waited for the child process to send an acknowledgment.
The information remained in the pipe until the user clicked on the 'Next' button. This interrupted the Tk main loop and called the button callback in the child. The button callback read the regex state information out of the first pipe, updated the TK window, and wrote an acknowledgment byte back into the second pipe. Control then returned to Tk.
The parent process was blocked, waiting to read the acknowledgment byte. When it received the byte, it returned control to the Perl regex engine, which ran the regex until control reached the next instrument.
To get the debugger idea to work, you need to take a regex, and insert
the (?{debug(...)}) items into it in appropriate places. The most
straightforward way of doing this is to look at the lexical structure
of the regex (that is, the source code) and transform it as a string.
The first version I did of the proof-of-concept debugger just asked you to type in a regex with the instruments already in place. If you wanted to debug the regex
/^\d+\.\d{2}$/
you would type in:
/(\d+)(?{&pause})(\.)(?{&pause})(\d{2})$(?{&match})/
which is obviously not very practical. I needed to automate this.
To automate this properly, you need to be able to understand the structure of regexes, and you need a good heuristic for where to put the instruments. Since this was a proof-of-concept, I didn't have to get the correct answer to either problem; it only had to be good enough. Here's what the application did:
$regex =~ s/((?<!\\)\w[*+?]*)/\($1\)(?{&pause})/g;
This puts an instrument after every \w character in the regex, or, if
the \w character is quantified with *, +, ?, *?, +?, or
??, after the quantifier. (An exception is made for letters that
are preceded by a backslash; I no longer remember why.) For example,
if the user were to type in
e*nt
it would be transformed to
(e*)(?{&pause})(n)(?{&pause})(t)(?{&pause})
After this,
(?{&match})(?!)
was appended to the end. match is a special callback that informs
the Tk interface that the entire regex has matched the target string;
(?!) forces the engine to backtrack after finding a match and to
search for other matches.
It should be clear that the technique I used for automatically instrumenting regexes did not work correctly in all cases. For example,
[xy]
would have been transformed to
[x(?{pause})y(?{pause})]
which is clearly a disaster. But it was good enough for a proof of concept.
It didn't seem likely to me that the little hack I had used could actually be extended to work robustly, because of oddities such as
[]a{}\]-]
and such. I considered trying to fix the bargain-basement instrumenter, and foresaw a future of unending bug reports complaining that my instrumentation had mangled one horrible regex after another. (Mike Lambert did pursue this, and the outcome is much better than I thought it would be; you can read more about that in his paper.)
I planned in 1999 to use one of two other approaches to instrumentation. One was essentially lexical: I could write a full-fledged parser for regexes. I didn't like this idea because it would mean maintaining the parser every time Ilya Zakharevich added a new regex feature. (This was happening a lot in those days.)
I felt that a fundamentally better approach was to take advantage of Perl's built-in regex parser, and instrument the regexes after Perl had finished parsing and compiling them. Details of this compilation process and the instrumentation of compiled regexes will take up most of the rest of this paper.
In August of 1999 I was at TPC3 and I showed the completed proof-of-concept to a few people. I also mentioned it to Dick Hardt, the president of ActiveState. I thought Dick might want to pay me to develop the regex debugger for real. Dick said he would think about it and get back to me.

At the very end of the conference I was stuck in a worthless and tedious meeting that I had foolishly agreed to attend. I spent a lot of time in the meeting thinking about the regex debugger and made many notes about how it might work and things that it might do. In particular, I thought of a name for it: Rx. (See figure 3.)
Perl uses two representations for regexes. Regexes are represented in
source code by strings such as (\d+)\.\d{2}$. When Perl compiles
your program, the regex is parsed and compiled into an internal
bytecode format by functions in regcomp.c. When the program is
run, the bytecode is interpreted, and the target string is examined
for matches, by functions in regexec.c.
To distinguish between regexes in these two representations, I'll call the string representation an 'S-regex' and the bytecode representation a 'B-regex'.
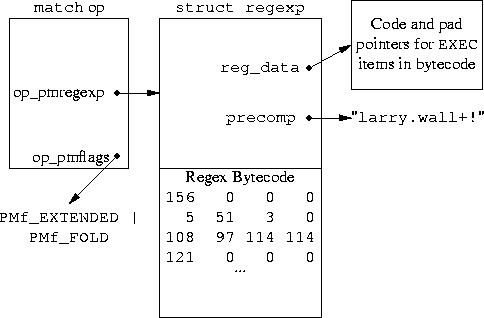
Most of a Perl program is compiled into an op tree, which is
essentially an abstract syntax tree of the program. There is a
different kind of op tree node for each Perl operator, such as + or
unlink. In particular, there is a match op node which indicates
that a regex match should be performed. This is the box in the upper
left of figure 4.
The match op node contains a pointer to a struct regexp (the large
central box) which contains, among other things, the B-regex that Perl
actually uses when it performs the matching. This is the part of the
diagram labeled ``Regex Bytecode''. The struct regexp also contains
some meta-information about the regex, such as the S-regex
(``precomp'') and the number of pairs of backreference parentheses.
The plan I had for the regex debugger was that instead of instrumenting the S-regex and then letting Perl compile the regexes into the bytecode, I would analyze the compiled B-regex itself, and construct a new B-regex. This way there was no chance of misparsing the regex.
I wasn't sure if the debugger would be run stand-alone (``debug this
regex, please'') or as part of the Perl debugger, debugging a complete
Perl program. In the latter case, I could get the existing B-regex by
following the pointer from the appropriate match node, mess round
with it, take the resulting B-regex and install it into the node in
place of the original.
In the former case, I could prompt the user for the regex of interest
and call the pregcomp function to transform it into a B-regex.
Then I would have a dummy function like this:
sub do_match {
my ($s) = @_;
$s =~ /dummy/; # This regex gets replaced by Rx
}
I would hunt through the op tree looking for the match node from
this function, throw away the bytecode for the dummy regex, attach the
user's B-regex instead, and invoke the function.
I wasted some time on something that was probably not too useful, because it was funny. I arranged that
print_bytecode(/(\d+)\.\d{2}/);
would work correctly, printing the compiled bytecode for the specified
regex. This looks very natural until you think about it a little, and
realize that the argument to print_bytecode() is actually a
boolean value that indicates whether the contents of $_ have
matched the pattern.
The print_bytecode function would ignore its actual argument, which
was useless. Instead, it would grovel recursively over the Perl op
tree until it found the place from which it had been called. Then it
would hunt up the match node, extract the B-regex from it, and dump that.
This was amusing and educational. It also came in handy later on.
All numerals in this section are decimal.
A B-regex always starts with the four bytes 156 0 0 0; this is a
magic number. When the B-regex is executed, Perl aborts if the magic
number is bad. Following the magic number are the bytecodes for the
'nodes' of the regex. These are the bytecodes that corresponds to the
S-regex larry.wall+:
0 5 51 3 0
1 108 97 114 114
2 121 0 0 0
3 222 18 1 0
4 3 51 2 0
5 119 97 108 0
6 0 57 3 0
7 1 51 0 0
8 108 0 0 0
9 1 51 2 0
10 33 0 0 0
11 222 0 0 0
I've arranged the bytes in four columns because the basic size of a bytecode 'node' is four bytes. The leftmost column is not part of the bytecode; it's just line numbers for reference.
The third and fourth column contain a 16-bit offset that says where the
'next' node starts. For example, the 3 0 in row 0 indicates that the
bytecode for the next node starts three rows down, at row 3. The 1 0
in that row indicates that the next node is one row down, in row 4. A
zero in this position indicates that there is no 'next' node.
Here I've broken up the bytecodes into groups to show which ones belong to the same node; I've also added comments to show the correspondence with the parts of the S-regex:
0 5 51 3 0 # larry
1 108 97 114 114
2 121 0 0 0
3 222 18 1 0 # .
4 3 51 2 0 # wal
5 119 97 108 0
6 0 57 3 0 # +
7 1 51 0 0 # l
8 108 0 0 0
9 1 51 2 0 # !
10 33 0 0 0
11 222 0 0 0 # (end)
The second column is the important one: It contains the byte that
identifies which operator is being represented. For example, a 51
stands for EXACT, which tells the regex engine to look for a
literal string. You can see that the 51 appears in nodes 0, 4, 7,
and 9, to indicate the larry, wal, l, and ! parts of the
S-regex.
The first column is a parameter, which is not meaningful for every
operator type. For EXACT nodes, it indicates the length of the
associated string which is to be matched exactly. In row 0, the
string is larry, so the parameter is 5; in row 7 the string is
l, so the parameter is 1. The strings themselves appear
immediately after the four-byte bytecode (in rows 1-2, 5, 8, and 10) and
are NUL-padded to an even multiple of four bytes. For example,
larry appears in rows 1-2 as 108 97 114 114 121 0 0 0.
Code 18 in the second column is the code for REG_ANY, which
means the . symbol. Code 57 is the code for PLUS, which
means the +. Code 0 is for the 'end' node. When the matcher
reaches the end node, it returns a success code back to Perl,
indicating that the entire regex has matched. The correspondence
between numbers and operators is defined by regnodes.h.
Quantifier operators such as +, *, ?, and {...} have arguments,
entire regexes to which they apply. The rule for the bytecode is that
the 'next' pointer for these operators points to the next bytecode
after the quantifier is finished; the code for the quantified regex
starts in the immediately-next bytecode. For example, row 6 is a
PLUS operator, and rows 7-8 are the part of the regex that is
quantified by the PLUS: In this case, the literal string l.
The 'next' pointer in row 6 points to row 9, which is the !, the
part of the regex that immediately follows the l+. Row 7 has zero
in its 'next' pointer, indicating that there is nothing that logically
follows the l itself.
Other kinds of nodes have other information associated with them. For
example, the {m,n} operator is represented by a CURLY node, and
with m and n stored in the following four bytes as two-byte
signed integers. (I don't know why they're signed, but the result is
that arguments larger than 32767 cannot be represented, and that
a{3,} is actually identical with a{3,32767}.) Character classes
(node type ANYOF) are followed by a 256-bit bit mask; bits are set
if the corresponding character is in the class.
a(?{...})b(?{...})c compiles as follows:
0 1 51 2 0 # EXACT 'a'
1 97 0 0 0
2 222 75 2 0 # EVAL (0)
3 0 0 0 0
4 1 51 2 0 # EXACT 'b'
5 98 0 0 0
6 222 75 2 0 # EVAL (3)
7 3 0 0 0
8 1 51 2 0 # EXACT 'c'
9 99 0 0 0
10 222 0 0 0 # (END)
Each (?{...}) compiles to a single EVAL node. Associated with
each EVAL node are two code pointers and a pad pointer. (There are
two code pointers because one points to the root of the op tree, and the
other points to the op node that is executed first. For example, in
$x+$y, the root is the + node, but $x is executed first.)
These three items are stored in the reg_data array, which is a member
of the regex's struct regexp. The argument associated with each
EVAL node (0 for the first EVAL node; 3 for the second) is
an offset into the reg_data array for the first of these three
pointers. This bytecode says that items 0,1, and 2 of the reg_data
array belong to the EVAL node of rows 2-3, and items 3, 4, and 5 of
the reg_data array belong to the EVAL node of rows 6-7. (There
are two code pointers because one points to the root of the op tree and
the other points to the op node that is executed first.)
When the regex engine needs to execute an EVAL node, it retrieves
the three pointers, sets up the pad, and executes the pointed-to Perl
op tree. When the op tree finishes executing, the regex engine
continues with the 'next' regex node.
In October 1999, I reminded Dick about the regex debugger, and he said that ActiveState was definitely interested, and they would let me know. But I didn't hear back from them until May of 2000; I was going to be in Vancouver the following month for the Perl Whirl, and Dick suggested I talk to them after the cruise. I met with the ActiveState folks on June 6 or thereabouts, and that's when I found out they were building a new development platform based on Komodo and wanted Rx to be part of it, and they wanted to demonstrate it at TPC4, which started on 17 July. I got to work right away.
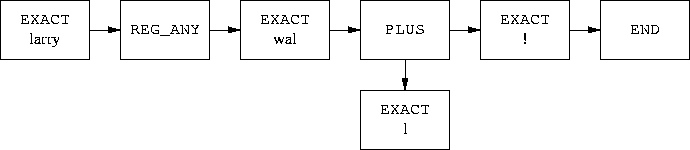
The regex bytecode represents an abstract syntax tree for the regex. In the
/larry.wall+!/
example above, the tree looks like figure 5. More complicated regexes
have more complicated graphs. (Strictly speaking, the graph is not
always a tree. For example, in /a(?:bc|de)f/ the 'next' node of
both bc and de is f.)
I decided that manipulating bytecode in C, with the corresponding memory allocation problems, was not going to be any fun. I decided to convert the bytecode into a Perl data structure; that way I would be able to write the instrumentation code in Perl instead of in C.
The first thing I did was to write a function, called
dump_compiled_regex, which would transform the B-regex into a hash
structure that represented the compiled code. The resulting hash is
called an H-regex. The H-regex for the example above looks like
this:
{
'REGEX' => 'larry.wall+!',
'0' => { 'TYPE' => 'EXACT', 'STRING' => 'larry', 'NEXT' => 3, },
'3' => { 'TYPE' => 'REG_ANY', 'NEXT' => 4, },
'4' => { 'TYPE' => 'EXACT', 'STRING' => 'wal', 'NEXT' => 6, },
'6' => { 'TYPE' => 'PLUS', 'NEXT' => 9, 'CHILD' => '7', },
'7' => { 'TYPE' => 'EXACT', 'STRING' => 'l', },
'9' => { 'TYPE' => 'EXACT', 'STRING' => '!', 'NEXT' => 11, },
'11' => { 'TYPE' => 'END', },
}
Each node is represented by a hash, and each has a NEXT member with
the key for the next node, except when there is no 'next' node. The
first node always has the key 0.
The PLUS also has a pointer to its 'child' node, which is the root
node of the tree that it quantifies. Some nodes have additional
information; for example, EXACT nodes have a STRING member that
says what string they must match. Similarly, the hash for the
CURLY node in the regex /a{3,7}/ would have an ARGS member
recording the 3 and the 7:
{ 'CHILD' => '2', 'TYPE' => 'CURLY', 'NEXT' => 4, 'ARGS' => [ 3, 7 ] }
A node representing the character class operator (ANYOF) would have
a CLASS member that would contain a 32-character string, which was
a raw dump of the bitmap.
Each node also contained some other information, not shown here, such
as the numerical code (TYPEn) that corresponded to the TYPE.
The structure as a whole also contained some meta-information about
the struct regexp from which the bytecode was extracted; the
REGEX item above is a representative example.
I then wrote a suite of Perl functions, headed by undump(), that
would transform an H-regex back into a B-regex. There were a few
complications here. The final code made three passes over the
H-regex: pass 1 would compute a reference count for each node (how
many nodes have this node as their 'next' node?); pass 2 would
recursively traverse the H-regex and construct the bytecode; pass 3
would fill the appropriate 'next' pointers into the bytecode once the
positions of all the nodes were known. Pass 1 was necessary
to ensure that pass 2 processed every node after all of its
predecessors.
Equipped with these utility functions, I could decompile the B-regex into a simple Perl data structure, tamper with the data structure, and compile the result back.
Adding the instruments was now a matter of transforming a Perl hash. the ActiveState folks suggested that I should put in instruments wherever it seemed reasonable. It was necessary to allow instruments to be enabled and disabled. One way to do this would have been to re-instrument the B-regex every time. But it was easier to put this feature into the callback that was actually invoked by the instruments. Each instrument was assigned an ID number, which it passed to the callback function. The callback function would have a table indicating which instruments were active and which were disabled. When the callback was invoked on behalf of an active instrument, it would update the graphic display and wait for a user command; when it was invoked on behalf of a disabled instrument, it would simply return control to the regex engine immediately.
Since I still wasn't sure how to decide where to put instruments, I
did what all software developers do when they don't know the policy: I
made the policy table-driven. The program put an instrument into the
H-regex immediately before every node whose opcode was listed in the
%is_instrumentable table. The last version I delivered to
ActiveState only added instruments before EXACT and END nodes.
Probably for production it would be wise to instrument REG_ANY
(.) and ANYOF (character classes) also.
There was one special case: Whenever the instrumenter saw an EXACT
node for a multibyte string, it broke it into a series of EXACT
nodes for each character in the string, and instrumented each one.
For example, suppose the input was /abc/, whose bytecode is:
0 3 51 2 0 # EXACT 'abc'
1 97 98 99 0
2 222 0 0 0 # END
The H-regex is simply this:
{
'REGEX' => 'abc',
'0' => { 'TYPE' => 'EXACT', 'STRING' => 'abc', 'NEXT' => 2, },
'2' => { 'TYPE' => 'END', },
}
The output from the instrumenter looks like this:
{
'REGEX' => 'abc',
'0' => { 'TYPE' => 'BREAKPOINT', 'NEXT' => '0e', 'ID' => 1, },
'0e' => { 'TYPE' => 'EXACT', 'STRING' => 'a', 'NEXT' => '0s1', },
'0s1' => { 'TYPE' => 'BREAKPOINT', 'ID' => 2, 'NEXT' => '0s1e', },
'0s1e' => { 'TYPE' => 'EXACT', 'STRING' => 'b', 'NEXT' => '0s2', },
'0s2' => { 'TYPE' => 'BREAKPOINT', 'NEXT' => '0s2e', 'ID' => 3, },
'0s2e' => { 'TYPE' => 'EXACT', 'STRING' => 'c', 'NEXT' => 2, },
'2' => { 'TYPE' => 'MATCH_SUCCEEDS', 'NEXT' => '2e', 'ID' => 0, },
'2e' => { 'TYPE' => 'END', },
};
The single EXACT node has been broken into three: 0e, 0s1e, and
0s2e. The instruments are the nodes with type BREAKPOINT and
MATCH_SUCCEEDS.
Since this is the first time we've seen any representation of an
instrument other than ``(?{...})'', it might be a good place to mention
that the ID member of the hash records the instrument's unique ID
number, which will be passed to ActiveState's callback later on when the
instrument is reached by the regex engine. The ID number is just for
documentation. When the H-regex is converted back to bytecode, the
IDs will be discarded. Instead, each instrument hash also has an
ARGS member, which I've omitted from this diagram, which is
included in the bytecode, and is interpreted by the regex engine as an
offset into the reg_data array, which holds the pointers to the code
and the pad for the instruments. Since every instrument has three
pointers in reg_data (I discussed this earlier, under Bytecode for Instruments) the value of the ARGS offset member is always exactly
three times the value of ID.
The bytecode that results from turning this back into a B-regex looks like this:
0 222 75 2 0 # EVAL (3)
1 3 0 0 0
2 1 51 2 0 # EXACT 'a'
3 97 0 0 0
4 222 75 2 0 # EVAL (6)
5 6 0 0 0
6 1 51 2 0 # EXACT 'b'
7 98 0 0 0
8 222 75 2 0 # EVAL (9)
9 9 0 0 0
10 1 51 2 0 # EXACT 'c'
11 99 0 0 0
12 222 75 2 0 # EVAL (0)
13 0 0 0 0
14 222 0 0 0 # END
$MULTIMATCH and TrailersActually I fibbed a little. The bytecode I just showed may be
incomplete, because it finds only one match. When there is more than
one possible match, you might like the debugger to continue searching
after it finds the first match. The proof-of-concept application does
this; the /g option in perl also does this. You can force any regex
to have this behavior by appending (?!) to the end. (?!) is a
pattern that never matches anything, so when the regex engine reaches
it, it is forced to backtrack.
At the very end of converting the instrumented H-regex back into a
B-regex, Rx would check to see if the $RX::MULTIMATCH flag was set.
If so, it would look backwards through the bytecode for END nodes and
snip them off if it found them. Then it would append a trailer to the
bytecode. The trailer was completely canned, and implemented the
(?!). I found the trailer by compiling the regex /(?!)/ and
dumping the resulting bytecodes; I then had Rx append those same
bytecodes to the end of any regex it got. After appending the trailer,
Rx would glue back the END nodes it had snipped off.
In some sense this wasn't elegant, but it worked just fine.
There are a number of tricky details that are hard to get right. For example,
the + operator is not always compiled as a simple PLUS opcode as I showed
earlier. That is only the simplest case, when the operand of PLUS is a
single node. If the argument is more complicated, + in the S-regex might
be represented in the B-regex as CURLYN, CURLYM, or CURLYX. CURLYX
is accompanied by a WHILEM node that causes a jump back to the CURLYX.
PLUS is the fastest and least general of these; CURLYX is the slowest but
the most general. The regex compiler examines the operand of the + and
decides at compile time what bytecode to generate. As a result of this,
perl -le '$z = "a" x 40000; print "yes" if "p${z}q" =~ /pa+q/'
yields yes, but
perl -le '$z = "a" x 40000; print "yes" if "p${z}q" =~ /p((?{1})a)+q/'
dumps core. In the first case the simple PLUS operator is used, and the
regex engine uses a simple loop to gobble up all the a's. In the second
case, the engine uses a CURLYX/WHILEM pair to implement +; this does a
backtracking search and pushes a lot of state information on the stack, which
eventually fills up. If the stack didn't fill up, the second match would
eventually fail, because the CURLYX actually corresponds to {1,32767}, not
to +.
This causes problems for the instrumentation. Consider the S-regex a+. This
is normally compiled to the following B-regex:
1 0 57 3 0 # PLUS
2 1 51 0 0 # EXACT 'a'
3 97 0 0 0
4 222 0 0 0 # END
If we instrumented this naively, simply inserting EVAL before the END and
EXACT nodes, we would end up with the following:
1 0 57 6 0 # PLUS
2 222 75 2 0 # EVAL (3)
3 3 0 0 0
4 1 51 0 0 # EXACT 'a'
5 97 0 0 0
6 222 75 2 0 # EVAL (0)
7 0 0 0 0
8 222 0 0 0 # END
Here we are trying to manufacture the bytecode that would correspond to
the S-regex (?:(?{callback(1)})a)+(?{callback(0)}). But this
bytecode is wrong, because PLUS does not work when its argument
contains an EVAL. PLUS is not general enough to handle such a
complicated operand.
The correct modification transforms the PLUS into a CURLYX/WHILEM pair:
{
'REGEX' => 'a+',
'0' => { 'TYPE' => 'CURLYX', 'ARGS' => [ 1, 32767 ], 'CHILD' => '1',
'NEXT' => '0n', },
'1' => { 'TYPE' => 'BREAKPOINT', 'NEXT' => '1e', 'ID' => 1, },
'1e' => { 'TYPE' => 'EXACT', 'STRING' => 'a', 'NEXT' => '0w', },
'0w' => { 'TYPE' => 'WHILEM', },
'0n' => { 'TYPE' => 'NOTHING', 'NEXT' => 3, },
'3' => { 'TYPE' => 'MATCH_SUCCEEDS', 'NEXT' => '3e', 'ID' => 0, },
'3e' => { 'TYPE' => 'END', },
}
The resulting bytecode is:
0 1 61 7 0 # CURLYX {1, 32767}
1 1 0 255 127
2 222 75 2 0 # EVAL (3)
3 3 0 0 0
4 1 51 2 0 # EXACT 'a'
5 97 0 0 0
6 17 62 0 0 # WHILEM
7 222 54 1 0 # NOTHING
8 222 75 2 0 # EVAL (0)
9 0 0 0 0
10 222 0 0 0 # END
This was the most complicated problem I had to deal with in the
instrumentation. A related, similar problem involved Perl's handling of
BRANCH, which is the opcode that implements the | operator. This
was less difficult to get right.
Another minor problem that arose from optimizations related to the
minlen feature. When perl compiles a regex, it computes a lower
bound for the length of a string that can match. For example, a simple
lexical analysis will show that /z*(pq|rst){7,12}n+/ cannot possibly
match any string that is less than 15 characters long. (pq|rst must
be at least 2 characters, so (pq|rst){7,12} must be at least 14.
n+ must consume at least one more character.)
The Perl match op checks the length of the target string against this
minimum, and if the target is too short, it reports failure immediately,
without even entering the regex engine. Part way through the project
the ActiveState folks reported that their callbacks were not being
invoked for the test
"ab" =~ /abc+/
It was because the minlen was 3 and the target string was too short.
It wasn't clear whether this would be a bug or a feature in the
debugger. We decided that I should turn it off for the time being, and
perhaps in the future it would be made into a user-configurable option.
It was easy to turn off: I simply set the minlen member of the
struct regexp to 0.
We now have enough background to understand how the regex debugger actually worked.
My agreement with ActiveState called for me to provide two functions,
called instrument and start.
instrument
SV *instrument(char *regex_string, char *options, SV *offsets)
This function would accept an S-regex (such as "larry.wall+!"), and an option
string (such as "gismox") and return the instrumented version of the regex.
In fact, what it did return was precisely the instrumented H-regex.
instrument was not too complicated. It manufactured a new, fake match op
node, analyzed the options, and set flags in the op node in the same way that
Perl would have. (This isn't hard; there is a one-to-one correspondence. For
example, x corresponds to the flag PMf_EXTENDED.) As a hack, I also
allowed control-L in the options to indicate that the regex should be treated
as if it were in the scope of a use locale declaration, and control-U to
simulate use utf8.
instrument then called dump_regex to construct the uninstrumented version
of the corresponding H-regex. dump_regex compiled the regex_string using
the same built-in pregcomp function that perl normally uses to compile every
other S-regex. The result was the B-regex; that is, the bytecode. It then
transformed the B-regex into an H-regex. The code to do this was all in C. If
I were doing it over again, I would probably have written the B- to H-regex
converter in Perl. As it happened, I had already written that code some time
before for some other purpose, so I just reused it.
instrument was now in possession of the uninstrumented version of the
H-regex. It called out to the Perl function Rx::_add_instruments which
analyzed the hash, installed the instruments, and returned the instrumented
version of the H-regex. instrument returned this structure to whatever code
in ActiveState called it.
startThe other function in the external interface was
void start(SV *rhrx, SV *target, RXCALLBACK callback)
This was the entry to the debugger itself. ActiveState was supposed to call this function to initiate execution of the debugger.
rhrx was the instrumented regex again, possibly modified by external
ActiveState code. target was the desired target string for the
match, and callback was a pointer to the callback function. start
was to execute the specified match and arrange for the callback to be
called whenever the regex engine encountered an instrument. How to do
this puzzled me for quite a while; at my initial meeting with
ActiveState in Vancouver I was not even able to explain how I would
accomplish this; all I could do was say I thought it would be possible
somehow.
The solution to this problem was a nice piece of hackery.
start first called Rx::undump, the Perl function that converted
the instrumented H-regex back into compiled bytecode. Rx::undump
returned two values: An SV containing the B-regex, and a count of the
total number of instruments. start then malloc'ed a new struct
regexp and installed the B-regex into it. It also smashed the
minlen value to 0 to disable the minlen optimization.
There's one essential item I have left out until now. An instrument is
essentially a (?{...}) item in the regex. To construct an instrument,
you have to do two things. The easy part is that you must install an
EVAL op into the appropriate place in the B-regex. undump has
done that. The harder part is that you have to construct the Perl code
that actually occupies the ... part of the instrument, compile it,
and install the pointers into the regdata member of the struct
regexp.
Perl's dynamic compilation comes the the rescue here. The code that
actually occupies the ... in the (?{...}) has the following form:
Rx::_xs_callback_glue(%d)
where %d is replaced with the ID number of the instrument prior to
compilation.
One beneficial feature of this scheme is that start does not need to
understand anything at all about the instruments. Instrument #17 is the
one whose code and pad pointers are in positions 51, 52, and 53 of the
reg_data array; therefore I can compile the appropriate code
(Rx::_xs_callback_glue(17)) and install the pointers without knowing
anything else about the location or function of instrument #17.
ActiveState might have rearranged or renumbered the instruments between
the calls to instrument and start; my code didn't have to care.
start malloc'ed a new struct reg_data to receive the pointers.
Then it ran a simple loop, once for each instrument. It used sprintf
into a fixed-size buffer to manufacture the string
"Rx::_xs_callback_glue(%d)" (with the %d appropriate replaced, of
course) and called sv_compile_2op to compile the resulting instrument
code. The result from sv_compile_2op was exactly the three pointers
that start needed to insert into reg_data.
start now had a complete struct regexp which was not yet attached
to the rest of the program. It needed to attach this regexp to some
part of the program that it could actually execute. It called
get_cv("Rx::do_match") to find the root of the op tree for the
function Rx::do_match, and then recursively groveled the op tree of
the function looking for the match op node. do_match, you may
recall, looks like this:
sub do_match {
my ($s) = @_;
$s =~ /dummy/; # This regex gets replaced by Rx
}
The groveling was done by a function named _locate_match_op, which
was adapted from my investigation of the weird hack described above
under Digression About Dummy Regexes. Which just goes to show that
when you come to kill a dragon, it never hurts to bring along all the
hardware you can find, because you never know what will be useful.
Upon finding the one and only match op in Rx::do_match, start
installed its artificially-manufactured struct regexp into it.
start then copies the callback pointer supplied by ActiveState
into a global variable, the_callback, so that _xs_callback_glue
(the instrument code) can find it again later. The last thing it does
is call_pv("Rx::do_match", G_SCALAR)---that is, it invokes
Rx::do_match in scalar context. Rx::do_match is as depicted
above, except that that the dummy pattern has had its brains scooped
out and replaced with our Frankenstein Monster bytecode.
Rx::_xs_callback_glueThe instruments themselves called Rx::_xs_callback_glue, which was an
XS function. The single argument to this function was the instrument ID
number. The function gathered up the values of $`, $&, $',
$1, and so forth, and build an array out of them; then it passed the
instrument ID number and the array to the ActiveState callback pointed
to by the_callback. The callback normally returned 0, but could
return 1 to indicate that it never wanted to be called again. In my
opinion this was a funny interface decision, but it was easy to
implement:
if (! let_finish_naturally) {
let_finish_naturally = (*the_callback)(id, items);
}
I think it's worth looking at the control flow in this application.
ActiveState's code calls start which is written in XS. start then
performs brain surgery on do_match, which is Perl, and calls it.
do_match invokes the Perl regex engine, which interprets the
bytecodes, which have a pointer to the Perl code instrument that I
compiled right out of an sprintfed string. The instrument invokes an
XS glue callback, which then invokes the real callback that was provided
by ActiveState.
This all worked fairly well, but there is one important feature that I
have omitted. One would like to present the user with a graphical
interface that displays the regex schematically, and allows the user to
enable breakpoints by clicking on the original S-regex. For example, in
the /abc/ case of the Instrumentation section, if the user
clicks on the c, you would like to enable instrument #3, which is the
one just before the c. Conversely, when the regex engine stops at
instrument #3, you would like to highlight the appropriate part of the
regex.
To do this, you need to construct a mapping between byte offsets in the S-regex and nodes in the H-regex. We tried several solutions to this before settling on one.
The big problem we had to contend with is that information is lost when Perl compiles the regex from its S-form into its B-form. The following three regexes all compile identically:
/a\rb/
/a\cMb/
/a\015b/
Supposing that instrument #3 is the one just before the b in each
case, it is clear that there is no way to know that instrument #3
corresponds to byte offset 2 in the first S-regex, 3 in the second, and
4 in the third.
There seemed to be three directions to go with this:
Of course, everyone hopes that (1) is going to be the best answer. For
example, Sarathy suggested that we might just assume that the user will
always write \r, never \cM or \015 or \x0f. But the
following example shows that that would not be enough:
m/fredbarney/x
m/fred barney/x
m/fred barney /x
Clearly no heuristic is going to know where the b is, or even come
close without actually looking at the S-regex to find the b.
Many similar examples will occur to the alert reader. (For example,
consider /#[a-z]#/.)
That left (2) and (3), both rather unpalatable. I tried (2) first, against my better judgment. (You will recall that the whole motivation for this bizarre exercise in bytecode-mangling was that I did not want to write and maintain a parser for regexes.) I did not have much success with this. The functions that were supposed to annotate the H-regex nodes with byte offsets kept getting confused. I could probably have fixed this eventually, but my heart wasn't in it.
(3) held out promise of being useful for some unrelated debugging purpose in the future, so in late 2000 and early 2001, we tried this approach.
This meant that I had to read and understand most of Perl's regex compilation process; up until then I had mostly dealt with the execution and interpretation process. The regex compiler walked the S-regex string byte by byte, adding nodes to the B-regex as it went. I modified it so that every time it added a bytecode, it also updated arrays of offset and length information. This was surprisingly pleasant, although I was taken by surprise a few times by the creative control flow in the compiler code.
I modified Rx to gather the offset and length information that had been
generated by the regex compilation process and to include them into the
H-regex. The result for /larry.wall+!/, for example, was
{
'REGEX' => 'larry.wall+!',
'OFFSETS' => [ 1, undef, undef, 6, 7, undef, 11, 10, undef,
12, undef, 13 ],
'LENGTHS' => [ 5, undef, undef, 1, 3, undef, 1, 1, undef, 1,
undef, 0 ],
'0' => { 'TYPE' => 'EXACT', 'STRING' => 'larry', 'NEXT' => 3, },
'3' => { 'TYPE' => 'REG_ANY', 'NEXT' => 4, },
'4' => { 'TYPE' => 'EXACT', 'STRING' => 'wal', 'NEXT' => 6, },
'6' => { 'TYPE' => 'PLUS', 'NEXT' => 9, 'CHILD' => '7', },
'7' => { 'TYPE' => 'EXACT', 'STRING' => 'l', },
'9' => { 'TYPE' => 'EXACT', 'STRING' => '!', 'NEXT' => 11, },
'11' => { 'TYPE' => 'END', },
}
$hregex->{OFFSETS}[4] has the value 7; this means that node 4,
the EXACT "wal" node, starts at position 7 in the S-regex.
$hregex->{LENGTH}[4] has the value 3; this means that node 4, the
EXACT "wal" node, takes up three characters in the S-regex. It is
not always clear what to do with some items such as | and WHILEM
and so on, but the problems are minor.
The major difficulty was that the new offset computation feature required a large patch to Perl! The debugger no longer worked with any released version. We got a promise from Jarkko to seriously consider incorporating the patch for upcoming versions, but the real solution to the problem was provided by ActiveState---someone there remembered that sometime in the past Ilya had made the regex engine pluggable; one could put together an XS module which would dynamically replace the entire regex compiler. I had to go away to Asia before I could look into doing that, so it was taken care of by Neil Watkiss of ActiveState.
At TPC4, ActiveState demonstrated the debugger for the first time, to
great interest. I decided there was no point in keeping it secret any
longer, so I gave a BOF session in which I discussed the original
(?{...}) hack and the proof-of-concept debugger. Several people were
interested, and I distributed the proof-of-concept code to them. Mike
Lambert took this the furthest, and showed that my original idea of
lexically instrumenting the S-regexes could be made to work better than
I had thought. His talk should be close to mine in space and time.
I'd like to see development on this continue.
One feature I love that Mike has put into his debugger is the option to step backwards through the regex, backing up over states already visited. This is possible because a regex has so little state information. I've wanted for ten years to see a debugger step backwards, ever since I heard that the SML debugger would do that.
My original agreement with ActiveState included a provision that my Rx code would be released under the Artistic License. I haven't done that yet because I want to give them a chance to get the full product to market, but I expect to release the code sometime later this year. Since the interface is completely generic (provide a callback that gets called when an instrument is encountered) people should be able to put all sorts of interesting interfaces onto my back-end. One particularly simple and useful interface would be a trivial profiler. ActiveState has put a lot of work into their own proprietary front-end and should be able to continue selling it no matter what other front-ends are developed.
The offset computation patch should probably go into Perl since it's cheap and since other applications might find the information useful.
I have a whole set of other ideas for improvements to the regex debugger which should be easy now that the infrastructure has been built. For example:
(X)*, you could get a warning that X will be captured only once.
If you wrote a regex with /.*X/ it could be corrected to /X/;
similarly (x|y|z) could be corrected to [xyz].
Even better, Rx could do static analysis of the regex and suggest
test cases. For example, if it sees that you have written a regex
containing XP*Y, it can recommend "XY" as a test case, initially
putting it in the ``does match'' set. If you found yourself surprised
that XY would match (and people often do,) you can move "XY" to
the ``does not match'' set and watch as Rx automatically rewrites your
regex to say XP+Y instead.
A lot of people put a lot of work into Rx. Ultimate responsibility may
have to go to Ilya Zakharevich, who put (?{...}) into Perl in the
first place. I don't know if he foresaw anything like Rx, but some
features are so obviously powerful that you put them in because you know
people will find uses for them that you can't imagine, and I'm sure Ilya
knew that when he put in (?{...}). Larry Wall probably deserves
credit for giving me the idea of using (?{print}) for debugging, even
if I don't remember it.
I'd like to thank Mike Lambert for being patient with me when I was too busy to look at what he'd done, and to all the people who came to my BOF.
The folks at ActiveState were a pleasure to work with and the project would have been an unmitigated delight of the schedule hadn't been so short. I'd like to particularly thank Ken Simpson and Neil Watkiss for working with me and for putting up with my own peculiar scheduling problems; David Ascher and Gurusamy Sarathy for the initial discussions of how Rx would work, and most of all Dick Hardt for being a great guy and for paying me a whole lot of money to actually build the thing.
I hope you will pardon my philosophizing a little.
I have a lot of very weird ideas. Some are things like ``If there were giant carrots floating in the skies, instead of clouds, then carrots would be worshiped as gods.'' Even among the ones I bother to write down, about seven out of ten are obviously not worth developing. Experience has shown that of the remainder, about two-thirds don't work out for one reason or another. One idea in ten is a good one.
The important thing to remember is that at the beginning, all these
ideas look equally bad. When I first got the idea to use (?{...}) to
invoke a callback in a regex debugger, it seemed absurd, a weird hack of
a little-used feature to do something that nobody was sure was worth
doing in the first place.
I think if I had been asked on day 1 to estimate the maximum possible value of this idea, I would have supposed it might be good for an April Fool's prank of some sort. But it turned out, after we put in the proverbial 99% perspiration, that it was a workable idea, and probably even has some commercial value.
So lesson number one is that most non-obvious ideas look pretty strange the first time you see them, and you shouldn't send them away even if they have horns and snaggle teeth.
The other thing that's really striking is that Larry had this idea in 1998, and as far as I can tell nobody paid any attention to him. Even I didn't pay any attention. Supposing that I read his message, which I probably did, I then forgot all about it until January 2001 when I happened across it by accident. Lesson number 2 is that Larry's a genius and we all don't pay as much attention to him as we should.
Thanks for your patience.

Return to: Universe of Discourse main page | What's new page | Perl Paraphernalia | Rx